
SLIPA: An IPA for Signed Languages
This page is devoted to Sign Language IPA (SLIPA), developed by me. This page discusses the reason such a system is needed, other types of transcription systems that exist, and also what the system is, how it can be used, and problems the system doesn't address. You can read this page straight through, or you can use the table of contents below to jump from section to section. For those not interested in reading the explanations behind the system, you might wish to jump straight to the summary near the bottom. (Also, reader Daniel Swanson has created a handy .pdf summary of SLIPA which you can download here. Thank you, Daniel!)
- Introduction
- Some Comments on Other Systems
- Place
- More on Place
- Movement
- More on Movement
- Handshape
- More on Handshape
- Two-Handed Signs
- Word/Phrase-Level Diacritics
- Indexing
- Summary
- How to Use SLIPA
- Apologia/FAQ
- Conclusion
- References
I. Introduction
There aren't many (if any) signed conlangs. It's my belief that the reason for this lies not in a lack of interest, but in a lack of a reliable method of transcription. Though several transcription systems have been attempted in the past (and are still in use today), they're not user-friendly, as they require the user to learn a new orthography which itself is dependent upon external programs or fonts in order to be used. Additionally, many of the orthographies were designed with a specific sign language in mind, making it useful for that particular signed language, but not for creating a new one. Thus, the available systems are not very useful to the creator of a novel signed language.
This page is devoted to an IPA for signed languages which I developed based on the work of David Perlmutter, who's studied the phonology and phonetics of signed languages (specifically, ASL) extensively. [Note: Though I'm entirely indebted to Dr. Perlmutter's insights for helping me to devise this system, I want to say up front that I am solely responsible for the system detailed on this page. That is, if you see something wrong with it, or it makes you upset, yell at me, not at Dr. Perlmutter.] Though this IPA will not be exhaustive, it's my hope that the design will lend itself easily to expansion, and that others will go on to create better ones.
This brings me to another point I want to make clear. I do not intend this system to be any kind of standard to which other systems should be compared. The sole purpose of this is to give people a method of transcribing signs, that they may go on to create signed languages. If someone else creates a better system, it's NOT my intention to try to hold up my system as being superior. [In fact, if I like their system better, I'll probably switch to it.] This is just a springboard off of which others can leap, if they so choose.
Below you'll find a detailed description of SLIPA. Understanding how it's used and how it was created will take some explanation, and the conventions I've developed are not necessarily theory independent (though they are based on research). Keep that in mind as you look through this page.
With that said, enjoy. If you find my system helpful, great. If not, I urge you to try your hand at devising a better one. The more people working on this issue, the better. If you have any questions or comments, I'd love to hear them.
II. Some Comments on Other Systems Out There
I know of a few transcription systems of sign language that are out there, and I'd like to take some time to discuss them. If you'd like more information, click here to download a (biased) article on sign language transcription systems. Though the article has its faults, there are actual pictorial examples of some of the transcription systems, which (I believe) I can't include here for copyright reasons.
•IIA: Word-for-Word:
Just to clarify, this is not a system of transcription, but an orthography. This is the traditional transcription method for ASL in linguistic studies of ASL syntax, semantics, etc. That is, in order to indicate an ASL sign, a definition of the sign is given in all caps. So, the English word for "snake" is "snake". If you want to indicate that you're referring to a sign in ASL, you capitalize all the letters, to get "SNAKE". This is a denotative system letting the researcher know to what sign one refers. In order to use the system, one has to know what the sign looks like—that is, nothing in this system enables the reader to understand how to make the sign. This system is fine (and, indeed, preferable) for syntactic analysis, for example, because typically one isn't interested in how a word/sign is pronounced, but just how the words/signs are put together. For that reason, the easier the system, the better. Imagine how absurd it would be if, in a paper on syntax, one had to give a narrow phonetic transcription of "We like Mary's pictures of ourselves" every time one used the sentence. Not only would it be tedious for the writer, it would be needlessly complex for the reader.
So, to sum up, there's nothing wrong with using the word-for-word system when discussing syntax, or when all interlocutors are expected to know the sign. If one wants to convey how the sign is produced, though, a different system will be needed. Now I'll discuss some such systems which have already been evinced.
•IIB: William Stokoe's Notation System:
The first transcription system was devised by William Stokoe (pronounced Stow-key), who was the researcher that brought it to the attention of the world that sign language (specifically, ASL) was a language like any other human language. That moment was truly a defining moment in both linguistics and the lives of Deaf people everywhere (not just in America). The transcription system that he used (which can still be found in very old ASL dictionaries) leaves much to be desired—not so much because the intention of the system was misguided in any way, but because the lack of research of ASL phonology made creating a usable system near impossible.
Essentially, the Stokoe notation system is like SLIPA in that it involves typewritten symbols that proceed from left to right. Most of the symbols that are used, though, can't be found in Unicode, and the movement symbols are rather idiomatic, and placed in a way that most typefaces can't handle. So, for the ASL sign for "snake", we have as the main feature a V with three dots over it which indicates a "bent V" handshape (in my notation, this is an Ś handshape). As secondary features, the "word" begins with a kind of "u"-looking shape, then the bent V, then what looks like a backwards sigma, then an upside down T, directly above which is a spiral. These other symbols are supposed to convey that the bent V moves away with a circular motion. Here's what it looks like:
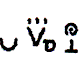
So that's what Stokoe's notation system is like. It wouldn't work well for a conlang for a number of reasons. First off, we don't have a font. So even to use it privately, a font would need to be created. That's no small task (especially given that some characters are supposed to appear above other characters. That is not easy, let me tell you). Second, it's not clear to me exactly how the system works. It appears that it would require a lot of study to fully "get it", so to speak, to the point where one could use it with any amount of efficiency. It was probably perfect for Stokoe, but we're not Stokoe. Finally, in order to communicate with others over the internet, first we'd have to learn the system, and then we'd have to devise an ASCII-friendly way of transcribing the notation. This could prove difficult because of some of the non-linear features of the script. Thus, in my opinion, Stokoe's notation would not be a good notation system to use.
UPDATE: I've found a couple things related to Stokoe Notation on the web. First, there is a font available on the web for Stokoe Notation which can be found here. Second, there is, in fact, an ASCII version of Stokoe Notation. Go here to read a description of this system, called ASCII-Stokoe Notation, invented by Mark A. Mandel in the late 70's for his dissertation at my alma mater, UC Berkeley. Again, though, this was to transcribe ASL, so Stokoe Notation has limited use for a language creator, unless you want to be confined to the handshapes, places, etc. of ASL.
FURTHER UPDATE: The information in the previous paragraph has been updated (specifically the name of the transcription system and the link). I've left the verbiage in tact for historical purposes, but the creator of the system has informed me that if you go to the end of the post linked to above, there is a section entitled "EXTENSIONS" that details how the system can be expanded to handle signs and elements of sign languages other than ASL. If you're interested in ASCII-Stokoe Notation, I encourage you to read through this section to see if it can work for you.
•IIC: Hamburg Notation System for Signs (HamNoSys):
This is a German system that still reads from left to right, but the roman alphabet has been totally abandoned. In its place, is a series of symbols which tell you things like handshape, orientation, movement, etc. The symbols aren't really that good at showing you visually what's going on, so chances are a lot of memorization would be involved. So, a question one might ask: What's the difference between memorizing a series of symbols which have no Unicode or ASCII equivalent, and memorizing a series of letters?
One benefit of using this transcription system is they have a handy little application which allows you to type in the font and give side-by-side interlinears (German-only, I think). Here's a site that describes it, and below is a sample from that site of what it looks like:
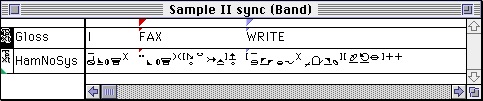
Despite these facts, I don't see any advantage to memorizing this system as opposed to memorizing an ASCII/Unicode system. The problems of internet communication would remain, as would the problem of every user learning a system. Plus, I think you have to buy the application.
UPDATE: You don't have to buy an application to use HamNoSys. You do have to download a font, but that can be found free here. What you have to buy is the SyncWriter, which is where I got my initial information from. This is an application that uses HamNoSys, but is not an application for HamNoSys.
•IID: Sutton SignWriting:
There's supposed to be no space between "sign" and "writing" above. Anyway, this appears to be the most popular system out there, but I have no idea why. It is, as I call it, user-antagonistic, as opposed to user-friendly.
First, let me tell you how the system works. The system was developed by Valerie Sutton and a few Deaf signers in 1974 after Sutton's DanceWriting was brought to the attention of the Deaf community (check it out here; the system is fascinating). The writing system itself is somewhat reminiscent of Blissymbolics—a picture-only language, like X. There are a very large number of pictures which relate directly to what signs look like. Some of the advantages of the system is that it's non-linear, so you can show both hands doing different things, and you can relate it to the speaker's face. Another big advantage is that it's the only system out there (I believe) that shows facial expression (i.e. brow movement and mouth shape). Much of the time, brow movement performs phrasal functions, but it can also relate to specific lexical items (e.g. ASL "WHO" has both rounded lips and lowered brows). Additionally, the actual "words" are more compact than are the "words" for, for example, HamNoSys. Below is a sample word for "teacher" (from SignBank.org):
I urge you to click here, so you can compare each system discussed so far. (In particular, compare Stokoe's and SignWriting's "Goldilocks" to HamNoSys's "Goldilocks". Are you kidding me?!?)
So that's what's good about SignWriting. Now the bad. First, of course (and most obviously), this system is useless to the online community. I've checked, and there is a program that will allow you to write SignWriting on the computer, but it's shareware, and it seems to only be for Windows (they claim otherwise, but I downloaded it, and only see .exe files). So, in addition to having to learn the system, you wouldn't be able to share your information with anyone. Additionally, based on my cursory analysis (all I can see is what's on the site), certain movements appear to have been misanalyzed. Thus, rather than analyzing a movement that goes from the head down with a circling of the hands as two separate processes (a downward movement and a secondary articulation that involves circling), the whole movement is encoded as a single process. This would force the system to have twice the number of necessary movement syllables, if circling were the only secondary articulation possible in a signed language (it isn't). Plus, since you need a program to use this system, the program will need to be changed and rereleased each time something new is discovered (I see evidence for this in sentences like, "You can type all of these symbols with SignWriter 4.3 right now", found here). Given that sign language is a human language, this should happen rather frequently.
So, even though SignWriting is (from what I can gather) rather accurate at representing signs, it's by no means usable online, and, therefore, not useful for our purposes.
•IIE: Glossing System for International Gesture (Gestuno):
Upon googling Gestuno, the international sign language developed by the World Federation for the Deaf (WFD) in 1973, I came upon a site that had a dictionary of Gestuno signs. Rather than having video clips and images, though, the author, David Bar-Tzur, created his own transcription system that bears a striking resemblance to SLIPA! Take a look at the dictionary itself here, and the explanation of the glossing system here. I had no knowledge of this system until after this page was essentially done. Upon e-mailing the author, I learned only that he and another had created the system. There's no further explanation on the web as to how exactly to use it, it seems.
•IIF: Enkonduko al Plena Signuno:
In case you don't speak Esperanto, the above says "Introduction to Full Signuno" (thanks to Dana Nutter for the translation help). The transcription system described in this introduction is a system that was created specifically to encode the created sign language Signuno, which is, apparently, Signed Exact Esperanto (i.e. there's a sign for every stem and affix, even if it makes no sense to encode them). A description of the transcription system (in Esperanto only, it seems) can be found here. Even if you can't read Esperanto, it should be easy to see that this transcription system has a pictorial form and an ASCII form. If you'd like to see the system in action, go here to see a dictionary (or maybe that'd be better translated as "wordlist"...). Here's a sample word below (the stem "koncert", English "concert"):
![]()

The system described on this page is actually very interesting, but it was designed only for Signuno, just as Stokoe Notation is only for ASL. The problem with trying to expand a system like this is that the ASCII form depends heavily on the specific places and handshapes used in Signuno. It can be done, but it would require a lot of work, and probably a good working knowledge of Esperanto (which, malfaliĉe, mi lakas).
•IIG: ASLSJ:
ASLSJ stands for "American Sign Language Sign Jotting". It's a system created by Thomas Stone to transcribe ASL, and it's really neat! It conforms to the ASCII ideal I adhere to for SLIPA, and, since it's just working with ASL, it doesn't have to rely on diacritics or Unicode characters to encode everything. Here's how it renders the ASL sign "TIME":
- ASL "TIME": DbvSvtv
What that says is that the right hand is making the G handshape and is bent at the wrist (= "Db"), and that the palm is facing down (="v"). The left hand is making the S handshape and the palm is facing down (="Sv"), and it's being touched by the right hand (="tv"). (For those that can't picture it, this sign basically looks like someone tapping their watch.)
I think this is a great system for ASL—perhaps better as an orthography than SignWriting. Its aim is to transcribe ASL not any sign language, so something larger is needed for our purposes, but for what it aims to do, I think this system is fantastic. After all, for any system to be useful to a Deaf signer, it needs to pass the text message test. If you can send it in a text message, then it's got a shot.
•IIH: Conclusions:
Based on my survey, it's my opinion that there's no transcription system for creating a sign language ex nihilo that exists that's usable online. So, unless one or more of these systems comes to the attention of Unicode, a new system has to be developed for online use. That's why I've developed the system detailed on this page.
Update: Sutton SignWriting has been added to Unicode. For more details, see follow the links here.
III. Place
The first topic I'll be discussing is Place (hereafter, just P). Place refers to the exact loaction(s) of a sign. A sign can have one place (like ASL "MOTHER", whose place is at the chin); it can have two places (like ASL "WE", where one touches the right and then the left chest area); it can have three places (like ASL "CHINA", where [I'm told] one mimics the uniform a Chinese soldier wears by touching the left chest, the right chest, and then just to the right of the belly button). A sign could have as many places as one can imagine. Plus, a P can be rather small (e.g. ASL contrasts the dimple and the cheek as two distinct places), or it can be rather large (compare the chest as a place to the chin). Signs can begin with a distinct P (like ASL "TRUE" that begins at the lips then moves outward and down), end with a distinct P (like ASL "PARKING", which ends in the palm of the weak hand, but need not start in any particular place), and begin and end with a distinct P (like ASL "DEAF", which begins at the strong side of the lips and moves to the ear). Some signs have no P's at all (ASL "AND", for example, is thought to consist only of a movement and a handshape change, the place of the beginning and end and the sign as a whole being rather unimportant).
So, what can be said about P's? Let me refer to the research of the hero of this webpage, David Perlmutter. Perlmutter remarked of ASL that a grammatical sign can consist of:
- A single P (e.g. ASL "MOTHER"), under the condition that there's a secondary movement (tapping, in the case of "MOTHER").
- An M (i.e. movement, discussed below), such as ASL "AND", mentioned above.
- An M followed by a P (e.g. ASL "WHEN", where the strong index finger starts in any particular place, and circles in towards the tip of the weak index finger, which is extended upwards).
- A P followed by an M (e.g. ASL"GO UP IN FLAMES", where the hands begin low, around the solar plexus, and extend upwards with wiggling fingers, with no particular end point in mind).
- A P followed by an M followed by a P (e.g. ASL "MEXICO", where two X hands touch both shoulders, and then move towards the center and meet near the bottom chest).
What Perlmutter found is that you could not have a grammatical sign where a P followed a P, or where an M followed an M (with no P). And, with one exception (which makes sense to me, by the way), a sign couldn't consist of a P with no secondary articulation (like finger wiggling).
For those who are familiar with spoken languages, think about this for awhile. Can you think of a type of consonant that can begin a word and end a word; that can serve as its own word with some kind of secondary articulation but not without; and that can't follow a similar segment without an intervening segment of a different type...?
Here's an idea. Why not say that P is like a consonant (C) just for the sake of argument? Let's try it out and see how far we get.
Okay, first test. Can a C begin and end a word? Yes sir. We've got words like "up", "pie" and "pup", just like the ASL signs for "WHEN", "GO UP IN FLAMES" and "MEXICO". So far so good.
Can a consonant serve as its own word? This may not be familiar to English speakers, but it wouldn't seem odd to a speaker of IT Berber, or to Japanese where a coda /-n/ takes up its own timing unit. Think of the letter/sound "l" (or [l]). You can say this one by itself and hold it for a long time. Try it. Sounds kind of like "ullllllllllllllllllllllllllllllllllll". Like the "al" in "metal". What you're pronouncing is a syllabic [l]—a consonant that can serve as the nucleus of a syllable (usually something only a vowel can do). Now, however, think about the "l" in "lever". I want you to imagine taking that "l" and making it into it's own word. Not holding it: Just saying it exactly as the "l" in "lever". It should prove impossible. Well, the difference between the syllabic "l" and the "l" in "lever" is just like the difference between a sign consisting of a P with a secondary articulation (like finger wiggling), and a sign consisting of a P without a secondary articulation. The secondary articulation is a kind of syllabifier, if I may. It performs the same function as the vertical line that goes underneath the [l] in the IPA (click here to see an image of the IPA chart) to make it syllabic.
For our final test, imagine a word like [sp]. Not something like "usp", with a syllabic [s], but something like the "sp" in "speed". Can you imagine that being a word? It should be difficult. Or something like [kp] or [tk]. It could become a word if you inserted a vowel of some kind, but on its own, no way. The same is true of a sign consisting only of two P's. And, in fact, try it on your own. Try to do a sign consisting of a flat hand that touches your forehead followed by a flat hand that touches your stomach. Can you do it without having some sort of movement in between the two P's (using only one hand, of course)? It should, again, prove impossible. Kind of like making a word out of the "sp" in "speed" without any epenthetic vowels whatsoever.
Based on the above, I'd say that thinking of a P like a C is a pretty good idea. After all, if you think about, consonants are concrete and easy to kind of pin down, whereas vowels can be slippery like fish. The same can be said of P's and M's. With a P, you're either at that place or you ain't. With an M, though, who can say if you do the same movement exactly the same way twice in a row? Hard thing to judge.
So, if P's are like C's, then they should be able to be categorized like C's. That is to say, it should be easy to identify P's and label them, the way it would not be for M's. It's entirely true that there are potentially a near infinite number of places on the body that can be a P, just as you can pronounce a [t] with your tongue tip in various places on the alveolar ridge with it still being a [t]. What I want to try to do is to set up some regions that are linguistically relevant. So even though a [t] can be pronounced in a number of ways, it's still acoustically a [t] until you move towards the teeth or back towards the hard palate. Similarly, the spot between your eyebrows is still the spot between your eyebrows even if there are two distinct spots two centimeters apart from one another.
Guided by the principles set forth above, then, I've come up with what identify as a workable set of linguistically relevant regions. Below are two diagrams: One showing regions from the neck down, and the other just on the face. This is because the face alone probably has as many (if not more) distinct regions as the body from the neck down. One would think the opposite, since the head is so much smaller, but evidence froom actual sign languages confirm the fact. There are a number of theories as to why this could be which I won't get into now. Below you'll find the images with numbers marking each point:
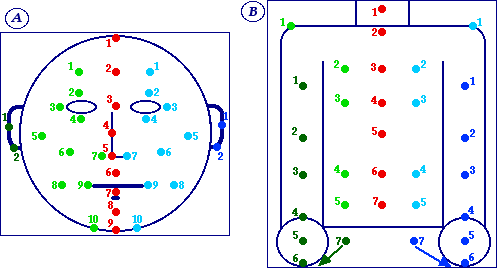
All right, above you'll see a poorly drawn face and a poorly drawn torso with various colored dots that are numbered. The numbers are just for ease of reference. The colors actually mean something. Specifically, if you have two spots on the body that are essentially mirror images of each other, there's no reason to come up with two distinct symbols. In the pictures above, the blue spots are mirror images of the green spots (the numbers correspond). In addition, there are some dark green and dark blue spots on the arms. These spots mirror each other, but in addition, each dark spot corresponds to an identical spot on the opposite side of the arm. So, for example, if this person is facing you, there's a dark green spot on the right hand with a dark green 5 next to it. That's supposed to indicate that a significant spot is the palm. However, there's another significant spot on the reverse side of the hand—the back of the hand. Rather than referring to these as two distinct spots, a diacritic will be used to distinguish between the two.
To describe these spots, let's start with something simple: The center spots. Each of the center spots has only one symbol associated with it. This symbol is a single lower case letter. Here's a description of each spot, starting with the face:
- h = The top of the forehead (where you'd find a widow's peak).
- f = The middle of the forehead.
- x = Right in between the eyes (x marks the spot?).
- r = The point of the nose in between the brow and tip (the ridge).
- n = The tip of the nose.
- u = The upper lip (or in between the nose and upper lip).
- l = The lower lip.
- d = The dimple in between the lower lip and chin.
- c = The chin (the bottom of it).
Those are the center spots on the face (the red ones). Now for the center (red) spots on the torso (and neck):
- t = The throat.
- k = The center of the collar bone (clavicle).
- m = The middle of the chest.
- s = The bottom of the chest (sternum).
- p = The solar plexus.
- b = The belly button.
- i = Below the belly button (where the intestines are).
These sixteen symbols comprise the central P's in SLIPA. They're of course not all the possible points, but they're what SLIPA encodes. The symbols for some of these don't give you that much of a clue as to what they refer, but I tried my best. It was important to me that each symbol be a single letter, as to contrast them from non-central P's in a notationally consistent way. This way, if you see a lower case letter, you automatically know two facts about it: (1) It's referring to a P, and (2) this P is a central P (i.e. it has no mirror image).
Now I'll discuss the other P's. First, let me discuss the green vs. blue P's. For the purposes of this page, I'm going to assume that the basic signer is right-handed. This is because I'm right-handed, and because all other humans must logically be exactly like me. No, no, the real reason is that you have to assume that a signer is either right- or left-handed for a sign language where most one-handed signs are not done with a specific hand, but with the signer's dominant hand. For that reason, if you defined a left P and a right P, you'd have different transcriptions for different signers. This isn't ideal. For that reason, SLIPA defines a dominant P and a non-dominant P. Dominant P's will be a two letter symbol, and corresponding non-dominant P's will be the same symbol underlined.
[Note: From what I know, most natural signed languages work this way. If one created a signed language that required absolute right/left P's but allowed (or worse: required) signers to use their dominant hand, you might need more powerful machinery than SLIPA could provide. This wouldn't be hard to create, though (e.g. putting an "r" before all right-hand side P's, and an "l" before all left-hand side P's), so I don't think it's anything to worry about.]
So, just to clarify, the two lists below (one for the head and one for the torso) are going to describe the light green P's (non-underlined) and the light blue P's (underlined). First, the list for the head.
- sf and sf = The side of the forehead.
- br and br = The (eye)brow.
- sy and sy = The side of the eye.
- ey and ey = Just under the eye.
- tm and tm = Just under the temple on the side of the head.
- ch and ch = The cheek (on level with the bottom of the nose).
- nl and nl = The nostril (not inside, but to the side of).
- dm and dm = The dimple of the cheek (to the side of the mouth).
- mt and mt = The corner of the mouth.
- sc and sc = The side of the chin.
That's the list for the head. Again, the underlined versions are the weak-side versions (on the left for right-handed signers; on the right for left-handed signers), and the plain versions are the dominant-side versions (right for righties; left for lefties). To do this using only ASCII symbols, simply use the two letter symbol with an underscore in between for weak-side P's. (e.g. sf would be s_f.) Now here's the torso symbols:
- sh and sh = The shoulder.
- pc and pc = The pectoral muscle (or general area).
- np and np = Just under the nipple (under the pectoral muscle).
- sb and sb = To the side of the belly button.
- bl and bl = The belt area.
The leftover symbols are the dark-colored symbols. The symbols are separated because the darker P's have four different realizations. This is because the ear and the arm can be easily turned and referred to while the body faces forward, wheras the same claim can't be made about the head and torso. Thus, you can have a dominant-side and weak-side version of the under side of the arm (the default reading), or you can have a dominant-side and weak-side version of the top of the arm. This leaves four possibilities. Rather than having four different symbols, though, I'm just having a single symbol with three different representations. The regular version is for the dominant-side of the under arm; the underlined version is for the weak-side of the under arm; the overlined version is for the dominant-side of the top of the arm; and the overlined and underlined version is for the weak-side of the top of the arm. Below is a summary of the what I detailed in this paragraph. First, the two ear P's. [Note: These types of P's will use three letters.]
- ear, ear, ear, and ear = The ear (near the middle), or behind the ear.
- rlb, rlb, rlb, and rlb = The earlobe (front or back).
These should be pretty self-explanatory. Note that the ASL verb "PUT ON HEARING AID" uses the back of the ear, or the ear P. Now for the torso P's:
- bcp, bcp, bcp, and bcp = The bicep (or tricep).
- lbw, lbw, lbw, and lbw = The elbow joint.
- frm, frm, frm, and frm = The forearm.
- wrs, wrs, wrs, and wrs = The wrist.
- plm, plm, plm, and plm = The palm (or back of the hand).
- knl, knl, knl, and knl = The knuckles, or the underside of the knuckles.
- fng, fng, fng, and fng = Either the underside or top side of one or more fingers.
[I apologize for the fact that the drawing in B doesn't really show the fingers that well (or, to put it more accurately, at all).]
To do the new ones with ASCII symbols, you put carons in between the letters for those that are just overlined, and & (ampersands) between the letters that are underlined and overlined. (E.g. p^l^m and p&l&m.)
As a note, what if you really did want to refer to an area behind the torso or head? Could such a sign exist? According to Kilian Hekhuis, one could and does. In SLN (or NGT), the sign for "KIDNEY" consists of a pointing motion towards one's kidney. Assuming a right-handed signer was making this sign, the area to which they would point would (roughly—I've never actually seen the sign) would be the P sb, but on their back as opposed to their front. To refer to this region, you can employ the method used with the three letter signs, i.e. sb (and, for left-handed signers, sb). In ASCII, it'd be s^b and s&b. If you must refer to the reverse side of the body for a central sign, you could probably simply underline it, as b (the reverse side of the bellybutton), but if that should prove too confusing, it may be overlined, instead: b. How to do it in ASCII? Notice that none of the two- and three-letter P's have identical letters. To insert a _ or ^, then, simply double the P: b_b or b^b.
Now that we've defined the face and torso, you might be wondering about the rest of the body. The rest of the body is used in signed languages, but (as far as know), not extensively. For example, you slap your dominant thigh and then snap to do the ASL sign "DOG". Nevertheless, if I had to wager a guess as to how many signs involve the area below the waistline in ASL, I'd say less than 5%. This is just a guess, but I think it's more or less accurate. Intuitively, it shouldn't seem strange that the area below the waistline doesn't figure prominently in most signed languages, because it would require a lot of bending and moving of the legs, which is something one doesn't usually do when standing or sitting. For that reason, the area below the torso doesn't figure prominently in SLIPA. However, I have gone ahead and defined that region, just for the sake of completeness. Here's a picture of the area below the torso:
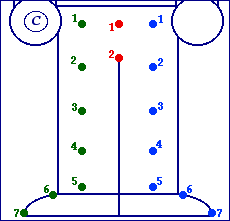
Now that you've got the picture, here are the symbols for the central P's:
- z = Where the tuft of the zipper would be on a pair of jeans.
- g = The groin.
You can probably guess why the two P's above would not figure prominently in any signed language, but there they are, just in case. Now for the "leg" P's. As you can see, they are dark green and dark blue, and thus have four realizations. Here's the list:
- btx, btx, btx, and btx = The upper thigh area (or, when reversed, the buttocks).
- thg, thg, thg, and thg = The thigh (either the front or the back).
- kne, kne, kne, and kne = The knee (either the front or the back).
- shn, shn, shn, and shn = The shin (or, when reversed, the calf muscle).
- nkl, nkl, nkl, and nkl = The ankle (either the front or the back).
- fot, fot, fot, and fot = The top of the foot (or, when reversed, the bottom, or sole, of the foot).
- toe, toe, toe, and toe = The toes (or, when reversed, the heel).
Note that the orientation switches for the P toe. Rather than being the top of the toes and the bottom of the toes, it's the toes versus the heel. This is based on the assumption that the bottom of the toes versus the top of the toes is not a distinction that a natural sign language would make. If it comes to my attention that there is such a sign language, I'll emend the system.
I'd like now to address the issue of neutral space. Neutral space is a concept that refers to the place that a sign is articulated when a specific place isn't necessary. You'll notice that there is no P "neu" for "neutral space". I did this intentionally, but not because I disagree with the idea of neutral space. I don't think it can be denied. However, it is my belief (and I've only studied ASL, so I can't back this belief up with any facts) that neutral space is a language specific phenomenon. That is, what is considered neutral space in ASL may not be what is considered neutral space in BSL, or in a signed language that you might develop. For that reason, I've left "neutral space" out of SLIPA. If you're creating a signed language, I think it would be to your benefit to define what "neutral space" is for your signed language. Is it in front of the chest? Is it closer to the stomach? Is it off to the speaker's dominant side? Is it in front of the face? Wherever it is, you can use the system discussed above to describe where exactly your language's neutral space is, and thereafter you can come up with a convention to refer to that neutral space.
Finally, before moving on, here's a table of all the P's of SLIPA. They'll be arranged in alphabetical order and explained, for easy reference. And, though the number of letters in a symbol does tell you whether the P can be mirrored and whether the P is reversible, I'll also include that information in the table. Finally, there will be a column which tells you whether the sign is on the head (H), torso (T) or below the torso (B), plus information on where to find that specific P on the figures above (A, B and C). Here it is:
| Symbol | Symbol Name | Region | Mirrored? | Reversible? | Description | Picture |
| b | Belly Button | T | No | No | This is the area in and immediately around the belly button. | B 6 |
| bcp | Bicep | T | Yes | Yes | The bicep (or tricep). | B 1, 1 |
| bl | Belt | T | Yes | No | The belt area (right at or above the waistline). | B 5, 5 |
| br | Brow | H | Yes | No | The eyebrow. | A 2, 2 |
| btx | Butt(ocks) | B | Yes | Yes | The upper thigh area (or buttocks). | C 1, 1 |
| c | Chin | H | No | No | The chin (specifically the bottom or point). | A 9 |
| ch | Cheek | H | Yes | No | The cheek (in line with the bottom of the nose). | A 6, 6 |
| d | (Chin) Dimple | H | No | No | The dimple in between the lower lip and chin. | A 8 |
| dm | (Cheek) Dimple | H | Yes | No | The dimple in the cheek (in line with the corner of the mouth). | A 8, 8 |
| ear | Ear | H | Yes | Yes | The ear (near the vertical center), or behind the ear. | A 1, 1 |
| ey | Eye | H | Yes | No | Just under the eye, or the eye itself. | A 4, 4 |
| f | Forehead | H | No | No | The middle of the forehead. | A 2 |
| fng | Finger | T | Yes | Yes | The top or underside of one or more fingers. | B 7, 7 |
| fot | Foot | B | Yes | Yes | The top of the foot (or the sole or instep). | C 6, 6 |
| frm | Forearm | T | Yes | Yes | The forearm. | B 3, 3 |
| g | Groin | B | No | No | The groin (below the Z Region). | C 2 |
| h | Head | H | No | No | This is the very top of the forehead, or top of the head. | A 1 |
| i | Intestine | T | No | No | Below the belly button and above the waistline. | B 7 |
| k | Clavicle | T | No | No | The center of the collar bone or clavicle. | B 2 |
| kne | Knee | B | Yes | Yes | The knee joint. | C 3, 3 |
| knl | Knuckles | T | Yes | Yes | The knuckles (or the underside of the knuckles). | B 6, 6 |
| l | Lower Lip | H | No | No | The lower lip. | A 7 |
| lbw | Elbow | T | Yes | Yes | The elbow joint. | B 2, 2 |
| m | Mid Chest | T | No | No | The middle of the chest. | B 3 |
| mt | Mouth | H | Yes | No | The corner of the mouth. | A 9, 9 |
| n | Nose | H | No | No | The tip of the nose. | A 5 |
| nkl | Ankle | B | Yes | Yes | The ankle joint. | C 5, 5 |
| nl | Nostril | H | Yes | No | Right next to the nostril. | A 7, 7 |
| np | Nipple | T | Yes | No | The nipple area (bottom of the pec). | B 3, 3 |
| p | (Solar) Plexus | T | No | No | The solar plexus (below the chest). | B 5 |
| pc | Pec(toral) | T | Yes | No | The pectoral muscle (to the side of the Mid Chest). | B 2, 2 |
| plm | Palm | T | Yes | Yes | The palm (or back of the hand). | B 5, 5 |
| r | Bridge | H | No | No | In between the tip of the nose and the brow. | A 4 |
| rlb | Earlobe | H | Yes | Yes | The earlobe. | A 2, 2 |
| s | Sternum | T | No | No | The bottom of the chest (the sternum). | B 4 |
| sb | Side (of the) Belly Button | T | Yes | No | To the side of the belly button (see Belly Button). | B 4, 4 |
| sc | Side (of the) Chin | H | Yes | No | To the side of the chin (see Chin). | A 10, 10 |
| sf | Side (of the) Forehead | H | Yes | No | To the side of the mid forehead (see Forehead), above the brow line. | A 1, 1 |
| sh | Shoulder | T | Yes | No | The shoulder area. | B 1, 1 |
| shn | Shin | B | Yes | Yes | The shin (or calf muscle). | C 4, 4 |
| sy | Side (of the) Eye | H | Yes | No | The side of the eye. | A 3, 3 |
| t | Throat | T | No | No | The throat and neck. | B 1 |
| thg | Thigh | B | Yes | Yes | The thigh (or hamstring area). | C 2, 2 |
| tm | Temple | H | Yes | No | Just under the temple on the side of the head. | A 5, 5 |
| toe | Toe | B | Yes | Yes | The toes (or the heel). | C 7, 7 |
| u | Upper Lip | H | No | No | Either the upper lip itself or the area in between the upper lip and the nose. | A 6 |
| wrs | Wrist | T | Yes | Yes | The wrist. | B 4, 4 |
| x | Center Brow | H | No | No | In between the eyebrows. | A 3 |
| z | Zipper (Z Region) | B | No | No | Where the tuft of the zipper would be on a pair of jeans. | C 1 |
The table above summarizes all the P's of SLIPA so far. I may add more if I think they're common enough to be necessarily included. What would be a great help to an enterprise such as this one would be a systematic survey of the world's signed languages, such as has been done many times with the world's spoken languages. Any takers?
IV. More on Place
Thus far we've defined what the places are, but we haven't said anything about how the hands can interact with them. For example, take the ASL sign "I". The location of the sign "I" is at the chest (the middle or the bottom; it doesn't really matter), but it's not just hovering in front of the chest. You actually touch the chest with the index finger of the dominant hand. So far, though, we have no way to distinguish whether a sign is located near an area or whether it touches that area. Now I'll introduce some machinery to do just that.
First, I'm going to introduce a diacritic: t (which stands for "touch"). You use this diacritic in conjunction with a P to indicate that that P is touched. How is it touched? For that further specification is needed.
A P can be touched with several parts of the hand. A P can be touched by one or more fingers (including the thumb); it can be touched by the palm or the back of the hand; and it can be touched by the side of the hand (non-thumb side, as the thumb would include the thumb side of the hand). Additionally, a P can be touched either by the dominant hand or the non-dominant or weak hand. To handle this, I've come up with a number of diacritic specifiers for the t diacritic. This is a list of them:
- Touch P with Thumb: t(th) or t(th)
- Touch P with Index Finger: t(in) or t(in)
- Touch P with Middle Finger: t(md) or t(md)
- Touch P with Ring Finger: t(rn) or t(rn)
- Touch P with Pinky Finger: t(pn) or t(pn)
- Touch P with Side of Hand: t(sd) or t(sd)
- Touch P with Back of Hand: t(bk) or t(bk)
- Touch P with Palm: t(pm) or t(pm)
If I wanted to be totally consistent, I could have "palm" as "plm", and have it overlined to mean the back of the hand, but given that these are diacritics, I thought that would be a bit much.
Additionally, since I'd rather have an overspecific system of which only a subset of the machinery is used than an inadequate system, I'm going to introduce another diacritic: f, for "faces". This diacritic can be used with the specifications above to indicate that the specified part of the dominant hand (or non-dominant hand) faces (but doesn't touch) the P in question. There are other ways to do this using methods described later on, but, again, I'd prefer redundancy to inadequacy. I'm not convinced that the method I describe below can handle everything, just as I'm not convinced that the f can handle everything. Hopefully with both of them, though, there's nothing that SLIPA can't handle. We'll see, though. Here's the spellout of the f diacritic:
- Have Thumb Face P: f(th) or f(th)
- Have Index Finger Face P: f(in) or f(in)
- Have Middle Finger Face P: f(md) or f(md)
- Have Ring Finger Face P: f(rn) or f(rn)
- Have Pinky Finger Face P: f(pn) or f(pn)
- Have Side of Hand Face P: f(sd) or f(sd)
- Have Back of Hand Face P: f(bk) or f(bk)
- Have Palm Face P: f(pm) or f(pm)
Another diacritic is the r diacritic, which stands for "rub". Sometimes a sign requires you to rub the P in question. For example, ASL "TRAIN" requires you to take the U handshape with your dominant hand and rub two fingers against the two fingers of your weak hand (also in the U handshape) back and forth. The rubbing motion tends to go from the bottom of the area to the top of the area, or around the area. What characterizes it, though, is that you start making contact at one spot and end making contact at a different spot without picking up your hand. Here's the r diacritic list:
- Rub Thumb Against P: r(th) or r(th)
- Rub Index Finger Against P: r(in) or r(in)
- Rub Middle Finger Against P: r(md) or r(md)
- Rub Ring Finger Against P: r(rn) or r(rn)
- Rub Pinky Finger Against P: r(pn) or r(pn)
- Rub Side of Hand Against P: r(sd) or r(sd)
- Rub Back of Hand Against P: r(bk) or r(bk)
- Rub Palm Against P: r(pm) or r(pm)
Directly related to the r diacritic is the b diacritic (which stands for brush). Brushing is different from rubbing because: (a) it's quicker, and (b) you begin by making contact but end by not making contact. Both rubbing and brushing can be used in conjunction with M's (movement) to insure that the direction of the rubbing/brushing is correct (if, in fact, it matters. In ASL, it seems to matter with some signs, but not with others, based on my experience). Here's the list for the b diacritic:
- Brush Thumb Against P: b(th) or b(th)
- Brush Index Finger Against P: b(in) or b(in)
- Brush Middle Finger Against P: b(md) or b(md)
- Brush Ring Finger Against P: b(rn) or b(rn)
- Brush Pinky Finger Against P: b(pn) or b(pn)
- Brush Side of Hand Against P: b(sd) or b(sd)
- Brush Back of Hand Against P: b(bk) or b(bk)
- Brush Palm Against P: b(pm) or b(pm)
All right, I've just introduced a new mechanism for SLIPA. So if you want to touch the mid chest area with the non-dominant index finger, you write /mt(in)/. This works for HTML, but not for ASCII. This is how you do it using only ASCII symbols.
Since both ^ and _ (common ways of showing diacritics) have other duties, I suggest you use an exclamation point ! to indicate that what follows is a diacritic. Thus, if you wanted to render the above sign in ASCII, you'd write it as follows: /m!t(i_n)/. There will be more diacritics to follow, and you do the same thing to make them ASCII friendly. You might have another exclamation mark to indicate that the diacritic is finished, but I don't think it will be necessary.
V. Movement
So if Place (P) in signed languages is akin to Consonants (C) in spoken languages, what are the Vowels (V)? Perlmutter argues that Movement (M) is akin to the vowels of spoken languages, and I agree. If you think about it experientially, this should seem rather intuitive. Consonants are kind of hard and concrete, and can't do much on their own. Place is this way. If you want to express a place with no movement, you just stick your hand somewhere and leave it there. Movement, on the other hand, you can do continuously in every which way until your arms get tired. Just like vowels, which you can pronounce continuously until you run out of air. Additionally, movement behaves like vowels because it's hard to tell if you have two distinct movements next to one another unless there's a P in between the two. The same can be said of vowels of different qualities, where it's hard to tell whether there are two distinct vowels, or whether they've formed a diphthong of some kind, unless there's a consonant stuck in between them. There are really a surprising number of parallels. Thus, for the purposes of this page, I'll be treating movement (M) as the vowels of signed languages.
So, movement. You can move your arms anywhere. How can one possibly classify it? Well, one thing to keep in mind is that we're only dealing with linguistic movement. So it's unlikely that a sign in a signed language would require one to move one's hand from one's strong-side toe, to the top of one's head, to the back of one's weak hand, to the small of one's back, to the sole of one's weak-side foot, to the center of one's strong-side eye, and then finishing inside one's mouth. That's just not something that's likely, and not something I want this system to capture. What I do want to capture is a general movement space. This space won't be located in any one place, but will just be an area that can be used to help define where exactly a given point moves. So, imagine a space like this:
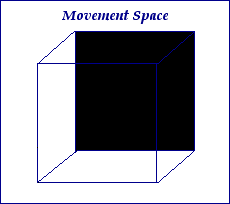
In the picture above, treat the black side as the back of the cube. Now that we've got our space, we can define some points in that space. Let's start with the back (which I'll refer to as the X plane). I'm going to define nine significant points (using only capital letters) in the back of the cube, which will be illustrated here:

All right, let's stop here for a minute. What we've got here, I want you to imagine, is a two dimensional area directly in front of a signer. The signer is facing us. Let's get some words that will help illustrate how this works. The ASL signs "NORTH", "SOUTH", "EAST" and "WEST" will be a nice set of examples. Each sign is formed by making the handshape of the first letter of each word and moving the hand in a particular direction (up for "NORTH"; down for "SOUTH"; right for "EAST"; left for "WEST"). [Remember: I'm assuming a right-handed signer for these examples.] Assuming these signs start in the mid chest (they don't have to, but let's just say), this is how you could represent the four signs (note: go to the section on handshapes for specific information on how handshapes are transcribed. For our purposes here, what's in brackets is the appropriate handshape):
- ASL "NORTH": m[N]XA
- ASL "SOUTH": m[S]XC
- ASL "EAST": m[E]XD
- ASL "WEST": m[W]XB
By using the movement space, we have a principled way of saying what moves from where to where. Or, as this examples shows, just what moves in what direction. The directional signs don't have to go to a specific region—they just need to move in one direction for a short distance. SLIPA allows you to do this.
This is a good time to bring up an important feature of the movement space. It doesn't matter which points you use, so long as the movement is defined. ASL "NORTH", for example, could be written in any of the following ways:
- ASL "NORTH": m[N]XA
- ASL "NORTH": m[N]CX
- ASL "NORTH": m[N]DE
- ASL "NORTH": m[N]HD
- ASL "NORTH": m[N]BF
- ASL "NORTH": m[N]GB
Each sign above says the same thing: You make an [N] handshape, start at the mid chest area, and move up for a short distance. Thus, the six words above are the same, but the following would be different:
- ASL ?: m[N]CA
I'm not sure if the word described above means anything in ASL. What it says is that you should make the [N] handshape starting at the mid chest area, and move it way up (so, instead of to, like, eye level, this would be above your head). It's certainly possible, but I'm not sure if it would mean something different from the regular "NORTH". Maybe it would mean "WAY NORTH", or something like that; I'm not sure. The point, though, is that it's different, because it describes a longer movement.
Based on the information given so far, you can probably figure out how to do linear movements. What about arcs, though?
First, let's see what won't work. Imagine you have a movement where you want to go in an upside-down "u" arc from the right to the left. You might think of a movement like DAB. This, however, wouldn't give you an arc, so much as two distinct movements: A straight line from D to A, and another straight line from A to B.
So, how to do it? I figure with the system I have set up, you can define three types of curves, using only the letters A, B, D and X (plus an extra notation I have to introduce). Here's the way it works:
- DAB = a wide arc touching points D, A and B.
- DB = a medium-sized arc touching points D and B, and passing in between points A and X.
- DXB = a narrow arc touching points D and B, and coming dangerously close to touching point X while passing in between points A and X.
The new feature, as you can see, is an overline. All this does is let you know that the path is an arc. In my experience, more specificity is not necessary. Below is a picture of each of the three arcs:
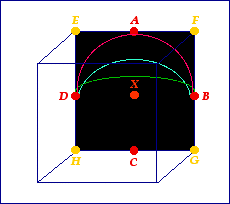
In the picture above, DAB corresponds to the pink ark; DB corresponds to the teal arc; and DXB corresponds to the green arc. Now, if you want to do the opposite arcs, you can do so using an underline:
- DCB = a wide arc touching points D, C and B.
- DB = a medium-sized arc touching points D and B, and passing in between points C and X.
- DXB = a narrow arc touching points D and B, and coming dangerously close to touching point X while passing in between points C and X.
One of the points of this system is so that it can be used online, and I realize underlines and overlines can't be used in, say, e-mail. A good ASCII equivalent, then, would be the following (using DXB as an example):
- D^X^B = a narrow arc touching points D and B, and coming dangerously close to touching point X while passing in between points A and X.
- D_X_B = a narrow arc touching points D and B, and coming dangerously close to touching point X while passing in between points C and X.
So inserting carons in between the movement points indicates an upward arc, and inserting underscores between the movement points indicates a downward arc.
A quick note: When trying to describe a vertical arc movement, overlines equal a leftward arc (where the peak is to the left), and underlines equal a rightward arc (where the peak is to the right). To use an ASL example, here's the current ASL word for "COLLEGE":
- ASL "COLLEGE": plmt(pm)[Bb(a)]CDF
This, so far, covers a two dimensional space. But, as should be obvious, sign languages are three dimensional languages. So, for example, consider the ASL sign "TRUE". This sign involves an outward movement. (Specifically, you make a G handshape and touch the tip of the finger to the lips. From there, the hand moves down and forward, with the orientation changing so that the index finger goes from pointing straight up to pointing towards the interlocutor.) How does one do that? Just add another dimension. Here's the third dimension, which I'll call the Y plane:
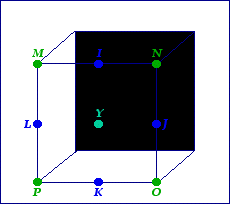
As you can see, the naming system continues. The midpoint goes from X to Y; the lettering, starting with I, begins at the top middle, and proceeds clockwise, picking out each midpoint; and the corners begin their lettering with the top-left hand corner, proceeding clockwise.
Before explaining the ASL sign "TRUE", let's see what this dimension by itself can do for us. Consider the ASL sign "GIVE 3:3" (i.e. "S/he gives him/her"). One could describe the movement as DB (or BD, depending on where the locus of the pronouns lie). That would get the movement down. But really, the arm is extended for the sign "GIVE". A DB movement would imply that the movement happened right in front of the signers chest. A better description would be to say that the movement is an LJ (or JL) movement, which would imply that the arm is extended (because it would need to be to get out to the Y plane). Thus, you get the following:
- ASL "GIVE 3:3": bcp[Ḿu(t)]JL
[Note: This is fine for a general description of the movement (I'd say that you can optionally arc the movement, so it could be either JL or JL. For simplicity's sake, I've used JL). For the actual ASL sign, though, indexing is needed. I'll discuss that later.]
So basically, the Y plane deals with movement further away from the body (or face). Now to the sign "TRUE". The advantage of having two planes is that you can describe three dimensional movement. So the sign "TRUE" (described above) can be represented as follows:
- ASL "TRUE": l[Gu(s)]AY
The overline here means that the arc goes towards the listener. An underline would indicate a kind of underneath arc that goes towars the speaker (this type of an arc is used in a sign like ASL "HIDE"). Also, though "TRUE" typically ends somewhere near the chest, the ending point isn't really important, so it need not be specified.
So, in order to be able to do a sign like ASL "TRUE", you need both the X and Y planes. Combined, this would look like the picture below:
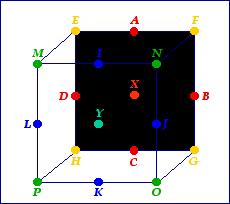
Admittedly, it's kind of weird-looking, but I've tried to color coordinate it so it makes some sense. Once the lettering system is understood, though, referring to the cube shouldn't be necessary. Additionally, you can even add a space, if you want. It doesn't seem that an extra plane would be necessary (e.g. for a language like ASL), but it might be. Thus, you could get a Z plane, with points QRST (the midpoints) and UVW1 (the corners). [I used 1 because we've already used X.] So, if there were a sign language that distinguished between an XY movement as well as a YZ movement (and maybe an XZ too), you might need the extra plane. To me, though, it seems like two should be fine.
Before the movement section concludes, I'd like to point out that the measures are relative. That is to say, you can use the cube however you want. You can define what the X and Y planes mean (i.e. how far away the Y plane is from the X plane), how long a half movement (e.g. XB) is, how this changes when it comes to the face. Also, say you want a full movement (e.g. DB) but the sign began in the middle of the chest. There's no reason why you have to start at X. Thus, you could have something like:
- ???: m[G]DB
That describes a sign using the G handshape that begins at the midchest and makes a full movement towards the weak side.
The main point is that this is just a framework; you can use it however you wish. You should explain how you're using it, though, if it's different from what's described on this page. It may be tedious to learn a new system for every new signed conlang, but it's better than nothing—and right now, nothing's all we got.
VI. More on Movement
One can do more with movement than just move. That is, you can go from A to B in more ways than just straight and curvy. Going straight and going in an arc movement are the two main methods, but there are secondary movements that can also be attached to movement. For example, the ASL sign "CALIFORNIA" is comprised of a move from one handshape to another (from the Ÿ handshape to the Y handshape), as well as a movement starting at the temple and moving away and down. Additionally, though, during the movement, the hand is wiggled. The hand doesn't wiggle while it's pressed against the temple, and it doesn't wiggle while the sign is being held at the end (Perlmutter had a lot to say about this phenomenon in his article, referenced below): It just wiggles while the hand is moving. This is what Perlmutter refers to as a secondary articulation, not unlike aspiration on a voiceless consonant (as with English stops in word-initial position, and other places). In this section, I detail various kinds of secondary articulations.
The first secondary articulation I'll mention is covered by the diacritic w, which stands for "wiggling" (what we discussed above). A wiggle is just that: A wiggle. A kind of back-and-forth sporadic movement of the hand while it's in motion. This can be seen in ASL for signs like "CALIFORNIA" (discussed above), "LANGUAGE" (some pronunciations), "FRENCH" (some pronunciations) and "GERMANY" (the latter two will be discussed later, if you happen to know those signs). To indicate that a movement involves wiggling, you just add a diacritic w after the movement, as with /mXAw/. This indicates an upward movement from the mid chest with the hand wiggling during the movement.
Another common secondary articulation that's related to wiggling is what I'll use the f diacritic to refer to: flashing (note: this is my term, as far as I know). Flashing involves the systematic opening and closing of the hand in a way that makes sense given the handshape. So, for example, if a V handshape is flashed, the index and middle fingers are bounced up and down, bending at the first joint of the finger. An Ś handshape, though, where the index and middle fingers are bent, would flash between the regular Ś handshape and the V handshape. The movement I just described might look like this: /m[Ś]XBf/. This is what the f diacritic does.
Another movement that's common is what I use the t diacritic for: The tumble movement. A tumble movment is kind of what a walking person looks like. Say you make a G handshape and pretend it's a person. If you want the person to walk, it kind of goes up and down with the movement, almost in small circles. The circles are always oriented such that they go from source of the movement towards the top to the movement's goal to the bottom, and then it repeats. A walking person might be described as follows: /m[G]XBt/.
Sticking with circular type movements, I'd like to introduce the h (helicopter) diacritic. I call this the helicopter diacritic because no matter where a sign moves, the circle's face must be parallel to the ground. One can imagine a helicopter moving all around and its spinning propeller (the main one, not the one on the tail) always remaining (relatively) parallel to the ground. A type of movment like this (using the G handshape to trace the path of the propeller) might be transcribed as follows: /m[G]XAh/ or /m[G]AGh/ or /m[G]FYh/, etc.
[Note: There are a couple more circular movements that are rather bizarre. If necessary, I'll add them, but for now, these two will do fine.]
Another type of movement is bouncing, which I represent with the b diacritic. Bouncing is kind of like tumbling, except that it doesn't circle in any way, and the bounce is a little bit higher. Imagine a ball bouncing across the sidewalk. Using the ASL classifier, it might look like this: /m[C]DBb/.
The last type of movement I'll mention is zigzagging movement, which uses the z diacritic. Zigzagging goes back and forth, relative to the direction of motion. I think it could be used describe a movement that goes side-to-side, or a movement that goes forwards 3 and backwards 2 really quickly, for example. Maybe not; that's just my opinion. Anyway, if you wanted to describe a zigzagging person walking away from the signer, you could transcribe it as: /m[G]XYz/.
So far, I've discussed the type of movement (i.e. it's all been path-related). Now I want to discuss some manner secondary articulations.
One obvious secondary articulation is to make a movement quickly. To do this, use the q diacritic. This specifies that whatever the movement is like, it's done more quickly than usual. So a person running might look something like: /m[G]DBq/.
Building off what we've got, the opposite of fast is slow, which you can specify by using the s diacritic. Thus, whatever the movement is, with the s diacritic, the movement is done more slowly than usual. Thus, a ghost slowly moving might be: /m[G]DBs/.
Another way to move is by pausing at regular intervals. To do that, use the p diacritic. So let's say you move forward a step then stop; move forward another step than stop; move forward another step than stop, etc. You might describe your movement as follows: /m[G]DBp/.
So, you can move fast, you can move slow, you can move pausing at regular intervals (kind of carefully). What else? Why not carelessly? To indicate careless, sloppy movement, use the i diacritic (for "inebriated"). So if an inebriated person is walking, it might be slow at times, then fast, then slow again. They stumble, waggle back and forth, zigzag, etc. In other words, this one is pretty loose, and up to the signer's discretion. Nevertheless, one should be able to get an idea of it. Here's what a drunk walking could look like: /m[G]DBi/.
If drunken movement is kind of fluid and stumbly, then another kind of poor movement is haphazard, or jerky movement, represented by the j diacritic. So in jerky movement, if there are any turns, they're taken rather sharply; rigidly. Rigid would be a good way to describe the movement. So a person walking rigidly forward could be: /mBDj/.
Before going on to mention just two more diacritics, I want to mention something about the nature of these diacritics. Unlike the other diacritics I have proposed thus far, these diacritics can be added together in different orders to produce different effects. And they can be duplicated. So, for example, you could have a movement /BDti/, where you have a tumble movement that's done carelessly (i.e. it goes straight from B to D, but maybe the "tumbles" aren't as crisp, but you could also have /BDit/, where you have a careless movement from B to D accompanied by full, non-careless tumbles. See how it works? The differences are subtle, and may be unimportant, if the language doesn't specify, but they could be important. Another thing you can do is double the manner ones to produce a larger effect. So if /BDq/ is a quick movement from B to D, then /BDqq/ is twice as quick, and /BDqqq/ is thrice as quick. At some point, the difference will become absurd, but the same can be said of vowel length (e.g. if [e] is a short vowel, then you can easily have a long vowel [e:], somewhat less-believably have a longer vowel [e::] [though Estonian does do it], and the more length markers you add, the more unbelievable it gets).
The point of introducing the concepts of combination and duplication now is that the following two diacritics are primarily used to modify other diacritics, though they can be used by themselves, if necessary. I'll now explain.
The first modifier diacritic I'll introduce is the augmentative diacritic a. This makes whatever the movement is larger. If you use it on ordinary movement, it will simply increase the distance (so /mXBa/ is like /mDB/, and /mDBa/ is even longer than /mDB/). If you use it on, say, the h diacritic, though, the result will be bigger circles. If you use it on the b diacritic you'll get bigger bounces, etc. Note that order is important. The movement /mBDab/ is a very long movement, from B to past D, with normal bounces. The movement /mBDba/, though, is a movement from B to D with big bounces. And, of course, you could have both. The movement /mBDaba/ is a movement from B to past D with big bounces. That's how it works.
The last diacritic I'll describe is the opposite of the augmentative: The diminutive diacritic, d. This makes a movement smaller or shorter than it ordinarily would be. So, used normally, the movement /mXBd/ would be a movement that starts at X and doesn't quite make it to B. The movement /mXBdd/ is an even shorter movement. Again, this can combine with anything. Thus, the movement /mBDbd/ is a movement from B to D with very small bounces.
That's all the secondary articulations I'm currently going to describe. Here's a list of them for easy reference:
- Used to Make a Movement Larger or Longer: BDa
- Used for Bouncing: BDb
- Used to Make a Movement Smaller or Shorter: BDd
- Used for Flashing: BDf
- Used for Helicopter-Like Movement: BDh
- Used for Careless, Drunken Movement: BDi
- Used for Jerky Movement: BDj
- Used for Regularly Paused Movement: BDp
- Used for Quick Movement: BDq
- Used for Slow Movement: BDs
- Used for Tumbling Movement: BDt
- Used for Wiggling: BDw
- Used for Zigzagging Movement: BDz
Before I conclude this section, I'd like to mention the ASL signs "FRENCH" (some pronunciations) and "GERMANY". Both of these signs involve one or both hands being put in a particular place and then the hand(s) wiggle(s). For example, for "FRENCH", you make the F handshape with your dominant hand and put it next to your ear. You then let it sit there and simply wiggle the hand for a little bit. SLIPA can handle this if you have a systematic way of distinguishing these M diacritics from P diacritics. So, for example, without the secondary articulation, the sign for "FRENCH" is /ear[F]/. It could very well have involved the thumb touching the ear, in which case it'd be /eart(th)[F]/. If that were the case, you could have an ambiguous transcription if you wanted to suggest that there was a tumble movement, since it's also represented with a diacritic t.
First, I want to note one thing. Perlmutter noticed that in ASL, a secondary articulation (e.g. wiggling) could only occur on a P if it was the nucleus of a syllable. In other words, if a P occurred in conjunction with an M of any kind (either before or afterwards), then wiggling could occur on the M but (crucially) not the P. Thus, it was only when the P was acting like an M that it could bear a secondary articulation. If you reason that a sign that consists only of a P will have to have a handshape, then the way SLIPA can unambiguously handle two diacritics is this:
- P diacritics such as t for "touch" will go directly after the P.
- M diacritics such as t for "tumble" will go directly after the M.
- If a sign has no P, an M diacritic may be added to the P, but it must occur after (not within) the handshape notation.
I realize we haven't discussed handshape yet (that comes next), but handshapes will always be enclose within square brackets [ ]. Thus, you could have /eart[F]t/. This sign would mean that the dominant hand is made into the F handshape placed next to the ear, and touches it (which part isn't specified). Then the hand does a tumbling motion. How it would do this, I don't know. It's probably impossible. I just used these two diacritics because they're represented by the same letter. The real ASL sign "FRENCH" is /ear[F]w/.
All right, that does it for movement. Now we can move on to handshape.
VII. Handshape
Perlmutter likened handshape to tone in a language like Chinese. This might seem bizarre to those who've seen sign language and have heard a tone language. To a speaker of a non-tone language like English, tone seems very ephemeral and hard to pin down, where as if you make your hand into a fist and move it from left to right, it's quite obviously different from making the peace sign and moving your hand from left to right. Nevertheless, if you think about it for a minute, it should make sense.
In language, tone is something that lives a separate life from, say, consonants and vowels. You can say "I'm going to the store" like a robot (i.e. in a monotone), and you can also hum or a sing a tune without any words. At the same time, the two (segments and tones) can't actually be separated (i.e. even if you say "I'm going to the store" in a monotone, you're still using a tone. And, even if you hum or sing a tune without words, you are either closing your lips and letting air pass through your nose [like an m], or your opening up your vocal tract and vibrating your vocal chords [like a vowel]). Adding some interest to the mix is the fact that you can change the tone of a word without affecting the segments, and vice versa.
Now let's look at handshape and in contrast with the already established segments P and M. First, you can kind of let your hand go limp and move it from left to right with ease (like saying "I'm going to the store" in a monotone). You can also use just your hand to fingerspell (i.e. just change handshape) behind your back, under your chair, above your head—anywhere (like humming a tune with no words). At the same time, even if you let your hand go limp, the hand will be in some sort of shape, even if it's not a linguistic shape (i.e. one that's used in a sign language). Just the same, even though you can fingerspell without any particular place in mind, you will still have to put it in a place. Finally, notice that you can move your hand from left to right no matter what shape your hand is in, and no matter how many times you change it. You can also take the same hand shape and move it all over the place.
Though it may not be perfect, the parallels between tone and handshape are hard to deny. For that reason, I choose to treat handshape like tone in SLIPA. How it will be done is this. Take the ASL signs for "I" and "my". For both signs, the hand touches the bottom chest (or thereabouts). The only thing that differs is the handshape and the point of contact. Thus, one can represent these signs as follows:
- ASL "I": st(i)[G]
- ASL "MY": st(p)[B]
Ideally, there would be diacritics that could be attached to either a P or an M, but Unicode can onlydo so much. For that reason, as you can see, the handshape is enclosed in square brackets following the P or M it's associated with. Here's an example of how it looks when there's a handshape contour that's associated with an M:
- ASL "AND": XA[C#S]
The above transcription describes a sign where the hand starts off in neutral space and moves a short distance to the speaker's right (for a right-handed speaker) with a hand shape contour switching from a C handshape (the hand looks like a C, so that the thumb is the bottom curve and the other four fingers are the top curve) to an S handshape (a closed fist).
That is essentially how the transcription of handshape works. To follow is a table of handshapes. In the best scenario, there would be a picture of the hand to follow each letter, but: (a) pictures of hands in the various shapes I need aren't readily available, and (b) even if they were, the page load time would just be unbelievable. So, I'll just have to make do with descriptions.
The signs will be listed in alphabetical order of the SLIPA symbol (and, where alphabetical order fails, I'll try to use Unicode order). After each symbol will be the symbol's name, and then after that, a description (in words) of what handshape the symbol corresponds to. To follow will be a list of symbols that correspond to handshapes that are similar to the one described. They're prelinked, so if you click on one, it'll jump directly to that symbol's description in the table.
Now, below you'll see a large number of symbols, but you'll probably be able to easily imagine a lot more handshapes. This is a balancing act that those who made the IPA had to perform, as well. After all, think about all the significant vowel glyphs the IPA has. Now compare that to how many different [i] sounds you can make. If you're careful and have a keen ear, I bet you'll be able to make more distinct [i]'s than there are distinct IPA vowel symbols. Nevertheless, the IPA vowel chart is useful because you can make do with a small amount of symbols and a series of diacritics that allow for more specificity where specificity is desired. I will try to make the same true of this. So, for example, say you want a handshape that's like an X handshape, but the knuckle is slightly more bent than the canonical X handshape. Just use X and say that it's slightly more bent. If there comes to exist a language that has two distinct handshapes—normal X and more bent X—then (and only then) will a new symbol be discussed. This is just as it is with the IPA.
All right, now, the table. If you don't understand a description, give me an e-mail, tell me what you don't understand, and I'll try to explain better (and if you have a better description in mind, let me know that, as well). And now, thanks to the magic of my ROKR phone, given to me as a Valentine's Day present, there are images available for some handshapes! Over the coming weeks
| Symbol | ASCII | Symbol Name | Description | Similar Shapes |
| 3 | 3 | Three | The index finger and middle finger are extended making a "V" shape, and the thumb is extended perpendicularly to the index finger (or as nearly as possible). View image! | 6, F, Ü, W, Ŵ |
| 4 | 4 | Four | The four non-thumb fingers are extended (spaced evenly) with the thumb tucked in towards the palm. View image! | 5, B, ß, Ŝ |
| 5 | 5 | Five | A flat hand with the fingers spread evenly apart and the thumb extended perpendicularly to the index finger. View image! | B, ß, Ó |
| 6 | 6 | Six | The tip of the pinky and thumb touch, with the remaining three fingers standing straight up. View image! | 7, F, Þ, W, Ẅ |
| 7 | 7 | Seven | The tip of the ring finger and thumb touch, with the remaining three fingers standing straight up. View image! | 6, 8, Ŷ |
| 8 | 8 | Eight | The tip of the middle finger and thumb touch, with the remaining three fingers standing straight up. View image! | 7, D, F |
| A | A | A | A closed fist with the thumb pointing upwards (towards the index finger's first segment). View image! | Ë, I, O, S, T, Ŧ, X |
| B | B | B | A flat hand with the fingers held tightly together and the thumb resting alongside the index finger. View image! | 4, 5, ß |
| ß | B\ | Beta | A flat hand with the fingers held tightly together and the thumb extended perpendicularly to the index finger. View image! | 4, 5, B |
| C | C | C | The four non-thumb fingers are extended up and held tightly together, as with a B hand, but then bent slightly, so that they are curved, as nearly as possible. The thumb, then, completes the curve, extending outward and bending, as if to form the lower half of the roman letter C. | Ć, Č, Ĉ, E, O, Ó |
| Ć | C' | C Acute | The hand is shaped as the C handshape, but with the middle, ring, and pinky fingers curled in towards the palm. | C, Č, Ĉ, L |
| Č | Cˇ | C Caron | The hand is shaped as the C handshape, but with the ring and pinky fingers curled in towards the palm. | C, Ć, Ĉ, Ü |
| Ĉ | C^ | C Caret | The hand is shaped as the C handshape, but with the pinky finger curled in towards the palm. | C, Ć, Ć, Ẅ |
| D | D | D | The tip of the middle finger and thumb touch, with the index finger standing straight up, and the remaining two fingers curled in towards the palm. | 8, F, G, K, L, P, X |
| Ḋ | D. | D Dot | The pinky and ring fingers are extended straight up, with all the other fingers curled in towards the palm, the thumb being covered by the curled fingers. View image! | 8, D, Đ, F, I, U, V |
| Đ | D- | Edh | The pinky and ring fingers are extended straight up, with all the other fingers curled in towards the palm. | 8, D, Ḋ, F, I, U, V |
| E | E | E | The four non-thumb fingers are bent so that the tips touch the top of the palm. The thumb is then curled towards the palm's center. View image! | A, Ê, X |
| Ë | E: | E Umlaut | The thumb is put into the palm and covered by all four fingers. View image! | A, Ê, S, T |
| Ê | E^ | E Caret | The index, middle and ring fingers are bent so that the tips touch the top of the palm. The other fingers are curled in towars the palm's center. | A, E, Š, X |
| F | F | F | The tip of the index finger and thumb touch, with the remaining three fingers standing straight up. [Note: Could also be referred to as the nine (9) handshape.] View image! | 3, 6, 8, D, Ḟ, W, Ẅ, Ŵ |
| Ḟ | F. | F Dot | The tip of the index finger curls over the thumb, with the remaining three fingers standing straight up. View image! | D, F, Ẅ, Ŵ |
| G | G | G | The index finger is extended straight up, with all the other fingers curled in towards the palm. [Note: Could also be referred to as the one (1) handshape.] | D, I, L, P, U |
| I | I | I | The pinky finger is extended straight up, with all the other fingers curled in towards the palm. View image! | 7, 8, D, Đ, F, G, Ï, P |
| Ï | I: | I Umlaut | The pinky finger is extended straight up, with all the other fingers curled in towards the palm, the thumb being covered up by the curled fingers. View image! | 7, 8, D, Đ, F, G, I, P |
| K | K | K | The index and middle finger are extended vertically, and the thumb makes contact with the second joint of the middle finger (the middle finger bends towards the thumb to compensate). The remaining fingers curl in towards the palm. View image! | U, V |
| L | L | L | The index finger is extended straight up, and the thumb is extended perpendicularly to the index finger, with all the other fingers curled in towards the palm. View image! | 3, D, G, I, Ü |
| M | M | M | The index, middle and ring fingers are extended outwards (not upwards). The thumb is brought underneath, so that the three fingers may rest on top of it. The pinky is curled in towards the palm. View image! | E, Ḿ, N, Ñ |
| Ḿ | M' | M Acute | The index, middle, ring and pinky fingers are extended outwards (not upwards). The thumb is brought underneath, so that the four fingers may rest on top of it (as nearly as possible). View image! | E, M, N, Ñ |
| N | N | N | The index and middle fingers are extended outwards (not upwards). The thumb is brought underneath, so that the two fingers may rest on top of it. The remaining fingers are curled in towards the palm. View image! | E, M, Ḿ, Ñ |
| Ñ | N~ | Enya | The index finger is extended outwards (not upwards). The thumb is brought underneath, so that the index finger may rest on top of it. The remaining fingers are curled in towards the palm. View image! | E, G, M, Ḿ, N |
| O | O | O | The thumb makes contact either with the tip of the index finger, the tip of the middle finger, or the space in between those two tips. The fingers must curve to achieve this. The remaining fingers match this curve as nearly as possible. View image! | A, C, E, Ó, S |
| Ó | O' | O Acute | Just like the O handshape, but the thumb and forefinger don't touch. (Note: This is referred to as the "bent 5" handshape in ASL.) | 5, C, E, O |
| P | P | P | The middle finger is extended straight up, with all the other fingers curled in towards the palm. View image! | D, G, I, Π |
| Π | P\ | Pi | The middle finger is extended straight up, but bent at the first joint, so that the angle between the first and second joint measures 90 degress. All the other fingers curled in towards the palm. | P, Ś, Š, Ŝ, X |
| R | R | R | The index and middle fingers are extended straight up, and then the middle finger is crossed behind and over the index finger. The remaining fingers are curled in towards the palm. View image! | G, U, Ü, Û, V |
| Ŕ | R' | R Acute | The ring and pinky fingers are extended straight up, and then the ring finger is crossed behind and over the pinky finger. The remaining fingers are curled in towards the palm. View image! | 8, F, I, R |
| S | S | S | A closed fist with the thumb curled in front of the closed fingers. View image! | A, Ë, I, O, T, Ŧ, X |
| Ś | S' | S Acute | The index and middle fingers are extended vertically (spaced evenly), but bent so that the first and second joint of each finger are perpendicular to one another. The remaining fingers are curled in towards the palm. | Š, Ŝ, U, Û, V, X |
| Š | Sˇ | S Caron | The index, middle and ring fingers are extended vertically (spaced evenly), but bent so that the first and second joint of each finger are perpendicular to one another. The remaining fingers are curled in towards the palm. | Ś, Ŝ, U, Û, V, X |
| Ŝ | S^ | S Caret | The index, middle, ring and pinky fingers are extended vertically (spaced evenly), but bent so that the first and second joint of each finger are perpendicular to one another. The thumb is curled in towards the palm. | Ś, Š, U, Û, V, X |
| T | T | T | The thumb is placed in between the index and middle fingers, with all fingers curling in towards the palm. View image! | A, Ë, I, O, S, Ŧ, X |
| Ŧ | T- | T Bar | A closed fist with the thumb extended outwards (like a thumb's up sign). [Note: Could also be referred to as the ten (10) handshape.] View image! | A, Ë, I, L, O, S, T, X |
| Þ | T\ | Thorn | The index, middle and ring fingers are extended vertically (spaced evenly), with the thumb extended perpendicularly to the index finger. The pinky is curled in towards the palm. | 6, 7, F, W, Ẅ |
| U | U | U | The index and middle fingers are extended straight up and held tightly together. The remaining fingers are curled in towards the palm. View image! | G, Ü, Û, V, Ŵ |
| Ü | U: | U Umlaut | The index and middle fingers are extended straight up and held tightly together, with the thumb extended perpendicularly to the index finger. The remaining fingers are curled in towards the palm. | 3, L, U, Û, V, Ẅ |
| Û | U^ | U Caret | The index and middle fingers are extended straight up (held together tightly), but bent at the first joint, so that the angle between the first and second joints measures 90 degress. All the other fingers are curled in towards the palm. | Ś, Š, Ŝ, U, X |
| V | V | V | The index and middle fingers are extended (spaced evenly) with the remaining fingers tucked in towards the palm. [Note: Could also be referred to as the two (2) handshape.] View image! | 3, Ś, U, Ü |
| W | W | W | The index, middle and ring fingers are extended vertically (spaced evenly), with the remaining fingers curled in towards the palm. View image! | 6, 7, F, Þ, Ẅ |
| Ẅ | W: | W Umlaut | The index, middle and ring fingers are extended straight up and held tightly together, with the thumb extended perpendicularly to the index finger. The pinky is curled in towards the palm. | 6, F, Þ, Ü, W, Ŵ |
| Ŵ | W^ | W Caret | The index, middle and ring fingers are extended straight up and held tightly together, with the remaining fingers curled in towards the palm. | 6, 7, F, Þ, U, W, Ẅ |
| X | X | X | The index finger is extended straight up, but bent at the first joint, so that the angle between the first and second joint measures 90 degress. All the other fingers are curled in towards the palm. | G, Π, Ś, Š, Ŝ |
| Y | Y | Y | Both the pinky finger and thumb are extended, with the remaining fingers curled in towards the palm. View image! | I, Ŧ, Ÿ, Ŷ |
| Ÿ | Y: | Y Umlaut | Both the index finger and the pinky finger are extended upwards, with the thumb being extended perpendicularly to the index finger. The remaining fingers are curled in towards the palm. | I, Ŧ, Y, Ŷ |
| Ŷ | Y^ | Y Caret | Both the index finger and the pinky finger are extended upwards, with the remaining fingers being curled in towards the palm. View image! | I, Ŧ, Y, Ÿ |
Again, this table is not exhaustive, but what's more useful than an exhaustive table is a non-exhaustive table with a method for further dilineating what handshape is intended. For more information on that, proceed to the next section.
VIII. More on Handshape
For those familiar with the ASL manual alphabet, you should notice a few odd things about the table above. First, there is no entry for Z or J. This is because the ASL manual letters Z and J are formed using the G and I handshapes (respectively), and performing a particular type of movement. Fair enough, you say. But what about H, P, and Q? There's an entry for P, but it doesn't look like the ASL letter P. Well, first of all, even though my system bears a striking resemblance to the ASL manual alphabet (think of it like the relationship between the IPA and the roman alphabet), there's no guarantee for a one-to-one mapping. Second, the letters H, P, and Q in ASL are formed with non-distinct handshapes. That is, H is formed with either the N or U handshape (depending on who does it); P is formed using the K handshape; and Q is formed using the G or Ñ handshape (again, depending on who does it). How do they differ from those letters? Orientation. That is, all of them have the same handshape; it just depends on how you turn your hand.
In order to address this issue, I decided to add some "diacritics". Think of these as the subsection of the IPA that allows one to make a distinction between a dental [d] and an alveolar [d], as well as retracted [e] and a regular [e]. The diacritics for handshape involve the movement of the wrist and lower arm. As I see it, the wrist can alter the orientation of a handshape in twelve distinct ways. [Note: There are potentially an infinite number of ways the wrist can be turned, depending on how much effort you're willing to exert, and how you define "ways". This is kind of like the "How many [i]'s can you distinguish" fact mentioned above. I've narrowed it down to twelve, which can be modified further if necessary.] These are those twelve ways:
- If the wrist is unbent...
- The lower arm can be turned so that the palm is facing away from the body.
- The lower arm can be turned so that the palm is facing towards the body.
- The lower arm can be turned so that the thumb edge of the hand is facing towards the body.
- If the wrist is bent at a 90 degree angle..
- The lower arm can be turned so that the knuckles or fingertips are facing away from the body.
- The lower arm can be turned so that the knuckles or fingertips are facing towards the body.
- The lower arm can be turned so that the thumb edge of the hand is facing towards the body.
- If the wrist is bent even further...
- The lower arm can be turned so that the knuckles are facing away from the body.
- The lower arm can be turned so that the knuckles are facing towards the body.
- The lower arm can be turned so that the thumb edge of the hand is facing towards the body.
- If the wrist is bent backwards...
- The lower arm can be turned so that the knuckles are facing away from the body.
- The lower arm can be turned so that the knuckles are facing towards the body.
- The lower arm can be turned so that the thumb edge of the hand is facing towards the body.
So, if you take the ASL letters K and P, K would be the K handshape with the wrist unbent and the palm facing away from the body. P, on the other hand, would be the wrist bent as far as it can go, with the knuckles facing away from the body.
Based on the table above, you can see that there are three orientations, and then four levels of, well, bentness, for lack of a better word. Bendyness, maybe. Anyway, to account for this, we need a simple set of diacritics. Note that these diacritics aren't necessary, and in some cases may overlap with the place diacritics. The same is true of IPA diacritics. The possibility of overspecification and redundancy, though, is better than not having enough specificity. So, if you have a handshape, [K], it can have one of four degrees of bendyness, based on the above list. They are as follows:
- For an unbent wrist: u
- For an bent wrist: b
- For an very bent wrist: v
- For wrist bent backwards (hyperextended): h
I think this is nice a system: All labials. Now there are three degrees of orientation. Basically, these degrees can be defined as "facing away", "facing towards" and "facing sideways". Thus, we can have the following:
- Facing away: (a)
- Facing towards: (t)
- Facing sideways: (s)
So, for ASL K and P, you have the following:
- ASL "K": [Ku(a)]
- ASL "P": [Kv(a)]
These diacritics would be ideal for explaining exactly how a handshape should be formed (e.g. for a manual alphabet). This level of specificity might become tedious when it comes to transcribing words and sentences, so it can safely be left out, I believe. Hopefully the mechanics of the movement and the place will be enough to let the reader/signer know just how the hand should be oriented.
Of course, there are some things which can't be handled with orientation. For these situations, I've developed the following symbols which are placed directly after the handshape:
- Finger Spreading:
- Fingers Spread More: )
- Fingers Spread Less: (
- Finger Bending:
- Fingers Bent More: >
- Fingers Bent Less: <
- Finger Tensing:
- Fingers Tensed More: /
- Fingers Tensed Less: \
- Hand Closure:
- Hand Closed More: }
- Hand Closed Less: {
These symbols are automatically ASCII-friendly because there's just no way to make further diacritics that could go over every capital letter that describes a handshape. Perhaps that's a good thing. We'll see.
IX. Two-Handed Signs
The system detailed thus far does a pretty good job of representing one-handed signs. But what about two-handed signs? This turns out to be a non insignificant question. Nevertheless, SLIPA does handle two-handed signs—just not as easily as one might hope. I'll now describe how SLIPA works for two-handed signs.
To contradict the sentence I just typed, before getting into how SLIPA can handle two-handed signs, I think it would be beneficial to note exactly what kinds of two handed signs there could be. I'll use ASL examples, but this should hold true for all signed languages. Here's a list of every type of two-handed sign:
- Weak Hand = Place: This type of sign doesn't involve movement of the weak hand. In this type of sign, the dominant hand does something with respect to the weak hand. So, for example, in the ASL sign "MEAN", the weak hand is made into a B handshape, with the fingers pointed up, and the side of the hand facing towards the body. The dominant hand (in the V handshape) then makes contact with the weak hand by touching the fingertips to the palm of the weak hand, rotating the hand (the dominant hand), and having the fingertips of the dominant hand make contact with the weak hand. Similarly, for the ASL sign "PARKING", the bottom of the dominant hand (in the 3 handshape) makes contact several times with the palm of the weak hand, which faces up, and is in a loose handshape (kind of like the 5 handshape). In this type of sign, the weak hand never moves: It simply serves as a kind of obstacle for the dominant hand to react to.
- Weak Hand = Place, but Performs: The typical way to imagine this type of sign is that the weak hand serves as a place, but then moves with the dominant hand. For example, with the ASL sign "HELP", the bottom of the dominant hand (in the Ŧ handshape) is placed in the palm of the weak hand, and then moved in a particular way (depending on the locus of the subject and object are). In this way, the weak hand serves as a kind of mobile platform.
- Weak Hand Mirrors Dominant Hand Exactly: What this means is that your weak hand does exactly what your dominant hand does, only backwards (as in a mirror). For example, the ASL sign "TEACHER" involves putting your hands in the Ḿ handshape, moving both hands up to ear level, and moving them back and forth. This mirroring can happen horizontally (e.g. with "TEACH", the hands are on a horizontal plane), vertically (as with "GERMANY", where one hand is right above the other, so they're on a vertical plane), or outwardly (as with "IS LIKE 3:1", where the hands [in the Y handshape] are placed one in front of the other, the being the outermost hand).
- Weak Hand Mirrors Dominant Hand Inversely: This is like the above mirror, except that the two hands will only be on the same plane when they're at the midpoint. So this is the kind of mirror where if you move your hand up, the image goes down; if you move your hand down, the image goes up. An example of this is the ASL sign "WHICH", where the hands (in the Ŧ handshape) are next to each other horizontally in the middle of the body, but at the point they're moved up and down inversely, such that when the dominant hand is at the top of a cycle, the weak hand is at the bottom. This can work horizontally (as with ASL "WHICH"), vertically (I can't think of an ASL example), and outwardly (again, I can't think of an ASL example).
- Weak Hand Copies Dominant Hand in Different Place: In other words, both the dominant hand and weak hand are in the same shape, and do the same thing, but they're in different, non-mirroring places. An example from ASL is the sign "SOLDIER". For "SOLDIER", both hands are put into the S handshape (maybe the A handshape), and both hands (the same place on each hand) tap the body twice, but they do it in different, non-mirroring places. The dominant hand taps the weak shoulder (sh), and the weak hand taps the weak belt area (bl).
- Weak Hand = Separate Entity: Finally, the weak hand could do something that's totally different from the dominant hand. This happens all the time with ASL classifier constructions. Imagine using classifiers to simulate a person (G handshape) walking towards a scared animal (Ś handshape). The person could slowly approach, and then the animal could move away, then maybe the person approaches more slowly, then maybe the animal moves closer to the person, then maybe right as the person gets next to the animal, the animal runs away. In this situation, there's no reason to believe that the two hands aren't acting autonomously.
Okay, that basically runs the gamut of two-handedgamot signs. Now back to the system.
First of all, I believe the system as presented thus far (with one additional stipulation) can handle (a) and (b) above. The stipulation is this: Unless otherwise specified, the weak hand, if used as a P, moves with the dominant hand. To illustrate, consider the ASL sign "SHOW 1:2". To do this, you take the dominant hand (G handshape) and touch the index finger to the weak palm (plm) and move the whole complex forward (XY). To describe this, you could do the following:
- ASL "SHOW 1:2": pmt(in)[Gb(s)]XY
Now imagine a sign where everything is identical, but the finger moves and the hand doesn't. To do that, you just need to add a second place that's different from the first place (which is the weak palm):
- ???: pmt(in)[Gb(s)]XYs
So since ASL neutral space is just below the middle of the chest, an XY movement is automatically going to be staying within the neutral space (since it starts there). By adding an overt P coda, though, you're specifying that the dominant hand moves and the weak hand doesn't. This is merely a convention you can use to distinguish the two.
To take care of (c) and (d) above we'll need to introduce a new mechanism to SLIPA, though it's slight. With (c) and (d), what you have are two types of mirrors (a regular mirror and an inverse mirror), and three different placements (horizontal, vertical, and outward). Also, these mirrors apply to the whole movement (or syllable, if you think of PMP max syllable). For that reason, I want to add something on the end that will say that the syllable is mirrored by the weak hand. Afterwards, there will be a designation to say whether the mirror is horizontal, vertical or outwards. If I had my druthers, I would make these X, Y and Z, respectively. However, there are math people that use Y for outwards and Z for vertical (upwards), so to foment confusion, I'll forego that. Instead, I'll just use H, V and O. This list summarizes that:
- Regular Mirror: >
- Inverse Mirror: <
- Image Aligns Horizontally: H
- Image Aligns Vertically: V
- Image Aligns Outwardly: O
This allows the transcribe to transcribe only the movement of the dominant hand, and thus cuts transcribing space in half. To show an example, here's the ASL sign "TEACHER" transcribed with SLIPA:
- ASL "TEACH": ear[Ḿb(s)]XYd >H
To transcribe ASL "TEACH" properly, you need another symbol on the end, but I haven't introduced that yet. (Hey, now that I think of it, might "TEACH" be at the forehead level, not ear level...? Meh. It's close.) Anyway, the transcription above tells exactly what the dominant hand does, and the />H/ tells us that the weak hand does the same thing on the other side of the head.
Now we've come to the last two, (e) and (f). Here I'm afraid SLIPA just can't do it simply. Because of the constraints of the medium, SLIPA is linear, so you can't layer lines (i.e. put one on top of the other). Thus, some tough choices had to be made. For signs like those described in (e) and (f), I decided to go this rout: Have two discrete transcriptions connected by a plus (+) sign. For best results, the transcriptions should be enclosed in parentheses (...) as well. The conventionalized understanding of this will be that the first transcription is what the dominant hand does, and the second is what the weak hand does. This method of transcription is powerful, though cumbersome, which is why I proposed the two shortcut methods above for (a) through (d). For (e) and (f), though, the more powerful machinery is necessary.
Let's take an example. First, an (e) example. This is where I feel bad for using the more powerful transcription, because there's only one difference that can't be handled. Working with the ASL sign "SOLDIER", the transcription would be as follows:
- ASL "SOLDIER": (sht(pm)[S])+(blt(pm)[S])
And, of course, the motion is repeated, but I haven't gotten to that yet. Anyway, as I said, this method can, technically, be used to describe any two-handed sign, though it's more cumbersome. Here's an example of each:
- ASL "PARKING": (plmt(sd)[3u(s)])+(s[Bu(t)])
- ASL "HELP 1:2": (plmt(sd)[Ŧu(s)]XY)+(s[Bu(t)]XY)
- ASL "TEACH": (ear[Ḿb(s)]XYd)+(ear[Ḿb(s)]XYd)
- ASL "WHICH": (s[Ŧu(s)]XAC)+(s[Ŧu(s)]XCA)
- ASL "SOLDIER": (sht(pm)[S])+(blt(pm)[S])
- ASL "G CL. (walks to) BENT V CL. (wiggling)": (pc[Gu(s)]DBtpc)+(pc[Ŧb(s)]w)
As you can see, the plus convention (as I call it) is powerful, but messy. It causes transcriptions to look more like equations than I'm comfortable with, but it does do the job. This is how SLIPA can handle two-handed signs. Again, it's not artful, but given the medium and the lack of alternatives, functionality is currently more important than artfulness.
Since a system is in place to handle two-handed signs, I'd like to introduce something very quickly that I haven't been able to introduce before. Many verbs in ASL can be nominalized by simply repeating the motion. So, to turn the verb "SIT" into the noun "CHAIR", you simply do the action performed by "SIT" twice in succession. To actually repeat the transcription would be a waste. Thus, I'd like to introduce the "repeat" notation. I've borrowed it directly from music, so that to repeat a sign once (in other words, to do it twice), you simply add :|| after the word. To repeat it three times, you add :||| after the word, and so on. So, here's what "CHAIR" looks like:
- ASL "CHAIR": ((fngt(in)[Ś])+(s[Uu(s)])):||
The main "action" in "CHAIR" is the touching that the dominant hand does. Adding the repeat sign indicates that that action is done twice. Add another line, and you'll get three times (which I believe I've also seen for chair). This will certainly cut down on transcription time, and the space used to do so.
X. Word/Phrase-Level Diacritics
One crucial element of ASL grammar, at least, that's been neglected up to this point is facial features. That is, one famous facet of ASL is the role that the face plays in phrase-level constructions. For example, the only difference between a yes/no question and the corresponding statement is whether the eyebrows remain neutral or whether the eyebrows are raised. The same feature (eyebrow raising) marks topics or focused elements. At the brow level, there's also brow lowering, which is associated with WH-Questions (or WH words—I'll talk about that in a minute). Branching out, there's the role of the eye(lids) and mouth. For example, if you want to say that an action is performed carelessly in ASL, you kind of half-lower the eyebrows, open the mouth a little, allow the tongue to protrude slightly, and perform the action (possibly imitating a lazy way of performing that action) (note: I'm indebted to David Perlmutter for this specific example). Lip rounding is also associated with ASL lexemes like "WHO" and "NONE". Facial expression, then, plays a large role in ASL grammar, and probably does in other natural signed languages (I have no data to confirm or deny this). Thus far, though, it hasn't been incorporated into SLIPA. Now it will be.
The role that facial expression plays in sign language grammar is tough. The only thing I can base my opinion on is what I know of ASL. So, let me discuss the various facets of facial expression in ASL. First, let's deal with the eyebrows. Eyebrow raising is, as far as I can tell, solely a phrasal-level unit in ASL. It either applies to a sentence as a whole (to indicate a yes/no question), or to a phrase as a whole (to indicate a fronted topic). Eyebrow is not a property associated with a given lexeme, but there's no reason to believe that it couldn't be. Could there be such thing as eyebrow raising associating with a segment (i.e. a P or M)? In other words, could there be a PMP sign where you could have neutral eyebrows for the onset and nucleus and then raised eyebrows for the coda? An interesting question that I won't answer just yet (but note that when I do the answer will be based on my personal experience and my opinion, and not on research of any kind).
Eyebrow lowering is an even more interesting phenomenon in ASL. I've heard that eyebrow lowering is a property of phrases (specifically, WH-Questions), and not of lexemes (I know the talk I heard this at, but I forget the name of the talk and the name of the presenter. I'll check up on that). However, if you look at an ASL dictionary, lexemes like "WHO", "WHAT", "WHERE", "WHEN", "HOW", "WHICH", etc. are described as having lowered eyebrows. For a personal anecdote, I once asked my ASL instructor (a native signer) about brow lowering. I believe I presented two questions to him, both of the form "HE SEE WHAT". I asked him which was correct, and then showed him two versions of the question: One where I lowered my eyebrows throughout the whole question, and one where I lowered my eyebrows only when I got to the sign "WHAT". He told me the latter was correct. However, I frequently saw him sign questions where his brows lowered throughout the question. Could it be a case of spreading from the WH-Word, or is brow-lowering a property of phrases in ASL? I don't know. One thing that seems certain, though, is that brow lowering is not a property of segments. I can't imagine that there could exist a grammatical ASL sign where brows went from neutral to lowered in the middle of the sign. But could a signed language do it?
Next comes the eye(lid)s. I've already mentioned how you can add an adverb "carelessly" to a sign in ASL through use of the eyelids, along with other facial features. The eyelids (in combination with the mouth) perform other functions in ASL. For example, the opposite of "carelessly" is "carefully". To do that, you purse the lips tightly and kind of focus the eyes (I don't know how better to describe that). Additionally, it's my observation that eye-widening appears to be a feature of some signs, though I can't remember any one specifically. Perhaps for a lexeme like "WOW", but that could be an artifact of the context in which a concept like "wow" is typically used. And then there are the eyes themselves. Eyegaze is very important in ASL. In certain contexts, eyegaze can function as a pronoun all by itself (note: I'm indebted to J Goard for this observation). Eyegaze is certainly something I'd like to know more about. For example, might eyegaze serve as a secondary articulation just like finger wiggling? Anyway, though, movements of the eyes, again, seem to be properties of words or phrases (or lexemes in their own right), and not properties of segments.
Finally, there's the lips. Lip rounding is associated with signs like "WHO" and "WATER" in ASL. The lips (and teeth) also play a role in ASL deictics. That is, the lips do something different if you're referring to something nearby, versus something slightly far away, versus something very far away. The lips also play a crucial role in the adverbials I already discussed like "carelessly" and "carefully". The lips perform countless functions, but they all seem to be associated with lexemes and not segments (or phrases, for that matter).
Oh, and I forgot one crucial one: The head. Tilting the head also plays a crucial role in ASL grammar. I believe its primary functions are to help pick out deictics and indexicals (e.g. a head tilt with a corresponding eyegaze is a common pronoun), but it also does other things. Oh, including the most important function, which I forgot until now: Negation. ASL has lexemes that can negate VP's and NP's and answer a yes/no question negatively (three different ones), but a head shake can perform all of those functions. This seems to be phrasal rather than lexical, but the head tilt associated with deictics (for example, the "NEARBY" or "HERE" or "THIS" deictic) is lexical. Head tilting or shaking is not associated with segments, though.
If I believed in Universal Grammar™, the above facts about ASL (based on personal observation and conjecture, rather than research) would be enough to claim that facial expression could never be associated with a segment in any conceivable signed language. Ever. Luckily, though, I'm a bit more skeptical. For that reason, I'll say that it seems to me, based on my observations, that facial expression is something that can be associated with lexemes or with phrases, but not segments. It's certainly possible to associate, say, a change in lip shape with a particular segment (you can try it out; it's not that hard), but it seems like signed languages don't make a habit of doing this. And there is a fairly good reason for this. Though facial expression is important, if it were liable to change segment-to-segment, not only would it be tiresome for the signer, but it'd be rather tedious for the watcher/reader, since s/he would have to constantly be watching the shape of the lips and the position of the eyebrows and the direction of the gaze, and so forth. Rather, it seems to me that facial expression seems to either add more "shape", if you will, to a given lexeme, or mark a phrase-level feature, which is perfectly fine, because you have more time to note the position of the brow in a phrase than you would if you had to check from segment-to-segment. Again, though, this is my theory based on no research: Take it with a bucket of salt.
The upshot is that SLIPA is going to treat facial expression as something that applies at the word level, or at the phrase level, solely. Kind of like intonation in the IPA (which, by the way, is not handled very well at all). This differs from handshape, though (which I related to lexical tone, and which, in turn, bears a close resemblance to intonation), because handshape is associated with particular segments, and can change from segment to segment.
Now I'll explain the various notations SLIPA uses to describe the abovementioned phenomena. First on the chopping block is eyebrows, since they're the easiest. Eyebrows can basically be up, down or neutral. Additionally, though, you can raise one eyebrow and leave the other down. I know ASL doesn't use this, but some sign language may, so I've made it relatively easy to encode. Here's how it works:
- Eyebrows Raised: ^^(...)
- Eyebrows Lowered: ˇˇ(...)
- Right Eyebrow Raised: ^ˇ(...)
- Left Eyebrow Raised: ˇ^(...)
That system should be fairly self-explanatory. What comes in parentheses is the entire number of signs affected. So if it's just one sign, like ASL "WHO", one sign goes in the parentheses. If it's a focused topic, though, an entire phrase goes in the parentheses (ditto for a whole yes/no question).
Next I'll deal with lipshape. As with the eyebrows, lipshape will be encoded at the beginning of a sign or phrase in parentheses. Unlike with eyebrows, though, the lips can do a bit more. Here's a list:
- Lips Taut (Drawn): L(d)(...)
- Expose Lower Lip: L(e)(...)
- Frown: L(f)(...)
- Hide Lower Lip: L(h)(...)
- Lips Loose, Slack, Lazy: L(l)(...)
- Pout, Pucker Lips: L(p)(...)
- Lips Round: L(r)(...)
- Smile: L(s)(...)
- Lips Drawn Back to Expose Teeth: L(t)(...)
Since we're on the lips/mouth, I may as well introduce the tongue. Though the tongue is rare in ASL grammar (I know of one naughty sign that uses it, as well as the "carelessly" adverb mentioned above), it could be used productively, so I'll include a diacritic for it, as well. This is it:
- Lick (Make a Licking Motion): T(l)(...)
- Tongue Sticks Out (Straight): T(o)(...)
- Pant: T(p)(...)
- Tongue Sticks Out (Corner): T(sd)(...) or T(sd)(...)
Now I'll move onto the eyelids. I make the eyelids distinct from the eyes because the eyelids perform particular functions, while the eye itself (the pupil) performs entirely different functions. I see the two as being fairly independent when it comes to sign language grammar. Here's a list of eyelid functions:
- Blink Eyelids: EL(b)(...)
- Eyelids Closed Completely: EL(c)(...)
- Eyelids Focused Narrowly: EL(f)(...)
- Eyelids Half-Closed: EL(h)(...)
- Eyelids Open Wide: EL(o)(...)
- Wink One Eyelid: EL(wk)(...) or EL(wk)(...)
I'll now move on to the eyes. I should mention now that there's a particular feature I'm not sure where to encode. Spefically, it's what's referred to as a "glazed look" in English, or having "glassy eyes". I'm not sure if this is a function of the eyebrows, the eyelids, the eyes, a facial expression, or a combination of two or more of those features. For that reason, I'd like to mention it, in case anyone has an idea on where to encode it. Now, the eyes. [Note: Each of the features below, aside from the last one, can be combined.]
- Eyes Ahead: E(a)(...)
- Eyes Down: E(d)(...)
- Roll Eyes: E(r)(...)
- Eyes to the Side: E(sd)(...) or E(sd)(...)
- Eyes Up: E(u)(...)
- Stare at Specific Place/Object: E(z)(...)
Let me briefly explain the last item on this list before moving on to functions of the head. To stare at a specific object means that the eyes follow or stare at a specific object or place in the real world. The real world can't be encoded, though, so a variable is used—in this case, z. In order to use this, it's the responsibility of the transcriber to say how one can fill the variable z. So, if staring at a particular person is sufficient for a third person pronoun, then the transcriber/creator of a signed language must state that, and can use the z variable as a shorthand for that description.
Okay, now on to functions of the head:
- Move Head Back: H(b)(...)
- Move Head in a Circle: H(c)(...)
- Move Head Forward: H(f)(...)
- Nod: H(n)(...)
- Shake: H(s)(...)
- Tilt Head: H(tl)(...) or H(tl)(...)
For the time being, that does it for word/phrase-level diacritics. There may be more things SLIPA will want to encode that I haven't gotten here yet, and when they come to my attention, I'll add them. For now, this can take care of a lot. True, it's not as elegant as in a system like SignWriting, but there's just no button on the keyboard whose function is "draw head". Maybe someday.
XI. Indexing
One thing that ASL does (and which, I have no doubt, many sign languages also do) is it assigns clausal arguments to a particular area (or locus, as its called), so that these argument can be referred to later on in the discourse with simply a turn of the head or a glance of the eye. This is what's called indexing. This process obviously requires a variable of some kind, and I'd like to make explicit exactly how SLIPA can handle that.
First of all, I think I should specify what kind of variable we're talking about. It's not just any old variable that is indexed. As I see it, there are four things that can be indexed:
- The speaker can index him/herself, or a group with which the speaker associates him/herself.
- The speaker can index the person or group to whom s/he's talking.
- The speaker can index a present non-addressed entity.
- The speaker can index a non-present (obviously) non-addressed entity.
This is an overspecified way of saying that the speaker can point to him/herself, or the group s/he is speaking for (i.e. "we"); the speaker can point to the one s/he's talking with; the speaker can point to something/one else that can be seen; or the speaker can set up a locus to refer to something that can't be seen. Taken cumulatively, this means that a speaker can refer to actual entities in the world pronominally. This should prove rather prosaic, as we do this all the time in English (and every other language on Earth, except for a couple that are very interesting). So if I say, "He's dead", you don't know who to be sorry for unless you know to whom I'm referring. This is old hat. In a signed language, though, the actual form of the pronoun can change depending on whether or not the referent's present, and where that referent is. It'd be like having as many different pronouns "he" in English as there are males in the world. In this way, handling reference is a problem for a signed language transcription system the same way it is for a semantics of (and isn't for a transcription system of) spoken languages.
Before moving on, a quick note: There's no reason that a signed language has to uniquely refer to objects present in the real world. Spoken languages get by without them, after all. But signed languages have the unique property of being able to easily refer to real word referents the way spoken languages can't. This is probably why most (if not all) natural signed languages do make use of indexation. For example, I bet the word for "I" in just about every natural signed language somehow involves motion towards oneself.
Now onto indexation. Basically, what SLIPA needs to be able to do is alert the reader of SLIPA that the place or motion of a given sign is dependent upon the physical location of a given entity in the world. One can either look upon this as fairly simple, or as fairly complex. I choose to look upon it as fairly simple. The result is that the machinery of SLIPA may not be powerful enough to handle all indexation, but it should be fairly simple to understand and manipulate. In places, it can help simplify transcription a great deal, making it advantageous to use indexation in some places in favor of either movement or place (or both).
To give a quick rundown of the system, let me present the following:
- For the Speaker to Refer to Him/Herself: 1
- For the Speaker to Refer to His/Her Interlocutor: 2
- For the Speaker to a Discourse-Relevant Entity: 3
- For the Speaker to Another Discourse-Relevant Entity: 4
- For the Speaker to Yet Another Discourse-Relevant Entity: 5
And the system goes on in the same way, as high as you need to count. Beyond 3, I can only imagine needing the extra variables if you're transcribing something with multiple pronouns (e.g. "She told him about its capabilities" in ASL, where you have three discrete third person referents).
Anyway, let me illustrate how this works. The personal pronouns in ASL all involve pointing with the index finger towards the chest area of either the speaker, the interlocutor, or a referent. With the machinery thus far, it's possible to describe the first person pronoun consistently. It's only possible to describe the second and third person pronouns, though, if one assumes a fixed position for the interoluctor and referent. To take care of all situations, though, one might describe the pronouns as follows:
- ASL "I" (First Person Pronoun): 1st(in)[G]
- ASL "YOU" (Second Person Pronoun): 2sf(in)[G]
- ASL "S/HE" (Third Person Pronoun): 3sf(in)[G]
As you can see, the system is perfectly symmetrical, but then again, people probably wouldn't stand for you going around and touching them on the chest every time you want to talk to (or about) them. Anyway, the "1" in the trasncription of ASL "I" is unnecessary, because the default interpretation of a P is that the P refers to the speaker. The "2" in front of the P of ASL "YOU", however, denotes that the general area referred to is the chest (or solar plexus. Some days I think of it as the chest, others as the solar plexus. Guess it depends how tall you are) of the interlocutor. The third person pronoun is a bit more complicated. The "3" indicates that the locus of the pronoun is the P (in this case the solar plexus) of the referent that isn't the speaker or the interlocutor. How do you figure out who the referent is? Or, for that matter, where the referent is? This is hardly an insignificant question.
Let's say you wanted to tell someone about three of your friends in ASL: Scott, Dave and Jon. In order to refer to them, you'd first set up a locus. So, for example, if I were telling someone about my friends, I might first use ASL "S/HE" and point to my right and fingerspell "S-C-O-T-T". I'd then point to the middle (but not at the interlocutor) and fingerspell "D-A-V-E". Finally, I'd point to my left and fingerspell "J-O-N". Hereafter, if I wanted to refer to one of them, all I'd need to do is point to the locus I assigned to each person, and that's how I'd fill the role of the referent.
In order for the above to work, one needs to assign a locus to each pronoun, as well as a variable. Then one can simply use the pronoun with the appropriate variable. In order to assign a locus, I might do the following:
- Assigning a Locus to Scott: ([G]XLsf(in))=3
- Assigning a Locus to Dave: ([G]XYsf(in))=4
- Assigning a Locus to Jon: ([G]XJsf(in))=5
Then to refer to them later in the discourse, you just use the ASL pronouns with the proper variable. Here's what they'd look like:
- ASL "S/HE" (Scott): 3sf(in)[G]
- ASL "S/HE" (Dave): 4sf(in)[G]
- ASL "S/HE" (Jon): 5sf(in)[G]
If one sets up a regular system, such that movement from right to left (for a right-handed signer) would automatically assign variables in order. This would obviate the need for "=3", "=4" and "=5" above. The important information (as to where exactly the referent is located) is indicated using the movement arrows. However, one might go another root. Imagine one is telling a story that takes place in a kitchen. Say there's a kitten that crawls up onto a chair, then from the chair jumps onto the table, and then eats all the food on the table, then jumps down onto the chair, and then back onto the floor. One could transcribe "chair" normally, or one could assign it a variable, like so:
- ASL "CHAIR": (((fngt(in)[Ś])+(s[Uu(s)])):||)=3
That's fairly complex looking. And one might also assign a "4" variable to the table. But now look how simple it is to say "he (the cat) jumped from the table to the chair":
- ASL "JUMP (FROM TABLE TO CHAIR)": 4[Vv(s)]XBb3
Since you've done all the work of transcribing the nouns already, you can simply use the variables to refer to them. Further, this is a more accurate way of describing the movement, as it's not so much that the movement traces an absolute pattern in space, but that the movements goes from one specific point to another (and that this is done with a bounce, or jump). The XB movement mentioned above is merely used so that the "bounce" diacritic can attach to something. Most importantly, it doesn't matter where exactly the "CHAIR" sign is done in space, for wherever it's done, that's where the cat will land when he jumps from the table (for his sake, I hope it's not too far from the table). [Note: To be more accurate, the handshape changes from a V handshape to an Ś handshape, and then back to a V handshape.]
Finally, I'd like to introduce a small piece of notation that seems like it'd be easy to introduce and understand. Imagine you had a signed language where verbs only inflected for subject. So say that a first person subject was at 1, a second person subject at 2, and a third person subject at a variable 3. To indicate that X person does Y, the action moves away from the subject. With our notation, this can be easily done simply by putting a negative sign in front of the number. So let's say you have a verb where you just move your fist out from the subject (say it means "to hit", or something). For a third person argument, you could transcribe it as follows:
- ??? "S/HE HITS": DB[A]-3
Above the movement DB just describes a long movement (the actual direction doesn't matter since the referent will change). The "-3", however, tells you that this long action will always move away from the third person referent that is the subject. Without the negative sign, describing a movement that went away from a referent, specifically, would be rather difficult. This should make it easier.
The variable nature of these variables allows you to be as specific as you want to be about location. So if you don't want to specify exactly where a sign is, and want to allow the signer simply to do the sign wherever, as long as a particular movement, handshape, etc., is achieved, the variables will still work. Hopefully this will be helpful, rather than harmful (i.e. not powerful enough), when it comes to transcribing a signed language.
XII. Summary
This section serves as a short summary of SLIPA. It will detail what each symbol basically looks like, and will link to where that particular feature is described.
- Place (P): Refers to the place where a sign is located.
- Symbols: Go here for a complete listing.
- Single Lower Case Letter: Specifies a P that is located in the center of the body.
- Two Lower Case Letters: Specifies a P that's on mirroring sides of the body (the right and left side). When this symbol is underlined, it specifies the non-dominant side of the body.
- Three Lower Case Letters: Specifies a P that's on mirroring sides of the body (both right and left and front and back). Underlining the symbol specifies the non-dominant side of the body, and overlining the symbol specifies the back side of the body (these two can be combined).
- Diacritics: Go here for a complete listing. P diacritics specify what exactly happens to the P in question (i.e. whether it's tapped, brushed, pointed to, etc.), and what enacts the action.
- Movement (M): Refers to how a sign moves from one P to another.
- Movement Space: Go here for an explanation and to see a picture of the movement space.
- Near Space (X Plane): Near space is defined by the uppercase letters A through D (for the cardinal directions), E through H (for the corners of the square), and X (for the middle). Movement is traced by connecting the dots. Overlining or underlining a given set of coordinates specifies that the movement is an arc movement.
- Far Space (Y Plane): Far space is defined by the uppercase letters I through L (for the cardinal directions), M through P (for the corners of the square), and Y (for the middle). Movement is traced by connecting the dots, much like with near space. The difference is that the action occurs further away from the body. To specify outward or inward movements, coordinates from both the X plane (near space) and the Y plane (far space) are used.
- Diacritics: Go here for a complete listing. M diacritics are used to further specify the kind of movement that's being used. They can describe fast movement, slow movement, bouncing movement, zigzagging movement, etc. Many of these diacritics can also be used with P's, when P's serve as syllable nuclei (i.e. when the P is a sign by itself).
- Handshape (HS): Refers to the shape the hand takes in a given sign.
- Handshape Listing: Go here for a complete listing. Handshapes are described using a single uppercase character which has both unicode and ASCII equivalents. In a transcription, a handshape is always enclosed in square brackets [ ]. If you want to show a contour (i.e. a change from one handshape to another), separate each handshape with a pound/number sign (e.g. [C#G]).
- Diacritics: Go here for a complete listing. Handshape diacritics are there to further specify how the hand is oriented towards the body (e.g. whether the wrist is bent, whether the palm faces the body, etc.).
- Two-Handed Signs: How to transcribe signs that use both hands.
- Transcription Devices for Two-Handed Signs: Go here for a thorough explanation.
- Mirroring: This is a sign-final notation that indicates that the non-dominant hand either mirrors the dominant hand exactly, or in an opposite way. The mirror can be an exact mirror [>] or an inverse mirror [<], and can be horizontal (H), vertical (V), or outward (O).
- Plus Notation: This is a specific kind of notation that can handle signs where each hand does something differenty. Follows the pattern: (...)+(...).
- Repeat Sign: The symbol [:||], used to indicate that an action is repeated (can act on one or both hands as a unit, or separately).
- Word/Phrase-Level Diacritics: These are word-/phrase-initial diacritics that apply to an entire word or phrase. Go here for a thorough explanation.
- Eyebrows: The symbols [^] and [ˇ] are used to specify either a raised or lowered eyebrow (respectively). Two of these symbols (representing both eyebrows) are put directly before the affected word or phrase (itself enclosed by parentheses).
- Lips: A capital L is used to indicate that the lips do something, and then further diacritics specify exactly what the lips do. The L symbol (along with its diacritic) is put directly before the affected word or phrase (itself enclosed by parentheses).
- Tongue: A capital T is used to indicate that the tongue does something, and then further diacritics specify exactly what the tongue does. The T symbol (along with its diacritic) is put directly before the affected word or phrase (itself enclosed by parentheses).
- Eyelids: A capital EL is used to indicate that the eyelids do something, and then further diacritics specify exactly what the eyelids do. The EL symbol (along with its diacritic) is put directly before the affected word or phrase (itself enclosed by parentheses).
- Lips: A capital E is used to indicate that the eyes do something, and then further diacritics specify exactly what the eyes do. The E symbol (along with its diacritic) is put directly before the affected word or phrase (itself enclosed by parentheses).
- Tongue: A capital H is used to indicate that the head does something, and then further diacritics specify exactly what the head does. The H symbol (along with its diacritic) is put directly before the affected word or phrase (itself enclosed by parentheses).
- Indexation: This is how real world referents are referred to (i.e. indexed). Go here for a thorough explanation.
- Referent Variables: Numerical variables are used to refer to a first person referent (1), second person referent (2), or a series of third person referents (3 through infinity). To assign a particular locus a variable, follow the transcribed sign (enclosed by parentheses) with "=#", for whatever number variable you choose. To refer to that variable again, put the number of the particular variable in front of the P that a later sign uses to refer to it.
- Negation: Simply place a negative sign [-] in front of a variable to indicate that the specified motion is away from that variable's locus, rather than towards it.
For more information on just how to use SLIPA, proceed to the next section.
XIII. How to Use SLIPA
•XIIIA: Introduction:
I hesitate to say it, but I believe this section is the most important section of all. You might be wondering, "Hasn't this whole page been a description of how to use this system?" Yes, it has. But, crucially, I haven't devoted any time to why and how this transcription system can be useful to you, as a language creator (or maybe as a transcriber for a real sign language). I would like now to devote some time to answering those questions.
First let me answer a question I've already answered: Why use SLIPA? The way I see it, SLIPA is the only usable transcription system out there that can be used to help create a signed language. Period. You can't use any of the methods discussed above for a number of reasons, foremost amongst which is the fact that the systems out there aren't powerful enough to handle new signed languages. They're powerful enough to handle the signed languages they were developed to handle, but in order to handle new natural signed languages (or new created signed languages which might do things very differently from natural signed languages), new symbols and mechanisms will need to be developed. Since these systems stem from one person (or a group of people), and since they make use of a computer application, a new version of the application would have to be designed specifically for your needs, which doesn't seem likely. Either that, or you can only work with hard copies (or maybe mouse drawing). SLIPA can be used with just an ASCII keyboard, and is less a collection of symbols than a framework. So even if SLIPA doesn't have a particular handshape you need, for example, it should be very easy to create a new symbol for the handshape and plug it into the SLIPA framework.
That, in a nutshell, addresses the question of "why". Now let me get to "how".
Before getting into the specifics, if you've never done so before, take a look at the IPA (click here). If you follow that link, you'll see a chart that has a bunch of symbols on top for consonants, and a bunch of symbols below for vowels. Below that, though, is a whole string of diacritics. I bet there's some diacritics that seasoned conlangers have never even used (anyone ever used the "linking" symbol?). Nevertheless, they're there. What are they for? Well, let's take the English word "hole", for example. If I wanted to let someone else know how I pronounce that, I'd probably just write [hol]. But that's not the best I could do. After all, to tell the truth, my vowel is probably unrounded. In fact, it's kind of a diphthong from a schwa-like thing to a velar approximant (hence, the unrounded part). And then the /l/ is certainly velarized, if not a velar /l/ itself. And, to be honest, I hold that /l/ for at least a half beat—longer than I linger on the /l/ in "laugh". And, of course, the word is stressed. So I might write it ['həɰɫˑ]. And who knows? Maybe my tongue isn't as advanced for this vowel as it is for someone who has my same vowels. And maybe it's a bit more centralized. Maybe my /h/ is a little more forceful, tending towards the pharynx. Maybe. But is this useful? If I was doing a phonetic study of my speech, yes. Otherwise, no.
Think of SLIPA in the same light. Use SLIPA for narrow transcription only when necessary. Take my example of describing ASL's K hand and P hand I mentioned above:
- ASL "K": [Ku(a)]
- ASL "P": [Kv(a)]
It would be useful to explain somewhere that this is what the K and P hands mean, but thereafter, to go ahead and use the symbols K and P, without the diacritics. This is what even phonologists do. For example, when discussing English, it's common practice to transcribe "teak" as [tik], even though the [t] is technically aspirated. This is because it's already understood that the [t] is aspirated. And if it isn't, it suffices to mention the fact once, and use [t] thereafter for simplicity's sake (and to save ink).
A parallel I might draw is with my own pages on the spoken languages I've created. In the phonology section of each language, I first have a chart that lists all the sounds of the language transcribed narrowly using the IPA. I then describe how the language's phonology works, and discuss a romanization system that I use throughout the rest of the site. The same thing can be done with SLIPA. Let me describe in detail how this could work.
•XIIIB: Describing Place:
By now you've seen the place diagrams above. Thus, you'll notice that there are a lot of places (and there can, no doubt, be more, and I'm sure the diagrams will grow accordingly). A given signed language might not use all of these places. For example, a given signed language might not use any P's below the waistline. Plus, I'm sure the P inventory of a given sign language can be larger or smaller than the P inventory of another signed language. So let's say you wanted to present a small one. You might use a table like this to present the P's of your signed language:
| Head | Torso | ||||||
| Above the Brow | Eyes, Nose and Ears | Cheeks | Mouth and Chin | Upper Torso | Lower Torso | Arms | |
| Central | f, h | n | l, d | k, m, s | p, b, i | ||
| Mirrored | sf | ey, sy | tm, ch, dm | mt, sc | sh, pc | bl | |
| Reversible | ear | bcp, lbw, frm, wrs, plm | |||||
With a table like that above, someone looking at a site about your signed language immediately knows all the places used in your signed language, and what they're capable of (provided, of course, that they have SLIPA as a reference, or know it already. The same is true of the IPA. This drawback is unavoidable). However, at th is point, you can use this guide and go on to create your own romanization. For example, even though [ear] is mirrorable and reversible, maybe your signed language will only make use of the mirroring aspect, and not the reversible aspect. That's perfectly reasonable. You might then want to come up with a romanization system that will simply let the reader know whether or not a sign is mirrored, as the reversible aspect won't play into your description. Also, signed languages can have allophonic variation. Take [ch] and [dm]. These are very nearby on the face. You might have a regular phonological rule that says that although the underlying phoneme is /ch/, it lowers to [dm] when preceded by a P that's on the torso. For that reason, in your romanization, you might only want a letter for the phoneme /ch/, since the allophony is predictable. The table just tells you what P's are used in a given sign language; not which ones are contrastive. Thus, in the language I described here, you couldn't have a sign distinguished only by place when the two places are [dm] and [ch].
As for the table itself, you can break it up however you want to. For example, I could've conflated "Above the Brow" and "Eyes, Nose and Ears" without jumbling up the table too much. However, a different language might make further distinctions, because it uses more P's in those areas than this one does. It's really your call. All you need to do is decide on a method of representation that best suits your signed language. And the same is true of a consonant table using the IPA used for a spoken language. There's no reason to have a "Uvular" column in a description of English, but it would be odd to have a "Dorsal" (everything from the velum backwards) column in Arabic, for example.
The secondary articulations for place may seem non-straightforward, since they deal with how the hands interact with place. Nevertheless, if you imagine the secondary articulations (touch, rub, etc.) as something like lip-rounding, it shouldn't be that hard to account for them in a romanization. So, if you rub a place, you could just add an /r/ after the P: /fr/ = "fr", etc.
•XIIIC: Describing Movement:
Admittedly, describing movement for a particular language isn't as easy. Presumably, a given sign language could allow any and every type of movement, so the coordinate planes will just need to be taken verbatim (and added to/emended as you see fit). However, one could imagine a signed language that only allowed specific types of movements, so that the language's movement inventory looked a lot more like a spoken language's vowel inventory.
As an example, imagine a language that only allowed a maximum of half a movement (i.e. from X to A but not from C to A) per sign. In this way, there would be a finite number of linguistically relevant movements (17, by my count, but I guess that depends on how exactly you count it). Given this situation, it might be possible to come up with some kind of chart, such as the one below (note: for this system, I assume that an XA movement is identical to a YI movement, and also identical to, say, a DE movement. That need not be the case, necessarily):
| X Plane | X Plane > Y Plane | ||
| Cardinal Movements | Horizontal | XB, XD | XJ, XL |
| Vertical | XA, XC | XI, XK | |
| Outward | XY | ||
| Diagonal Movements | Rising | XE, XF | XM, XN |
| Falling | XG, XH | XO, XP | |
As you can see, in this system, all movement is initiated from the center, and, if this were my language, I'd define the center as the initial P of the sign (and if a sign had no initial P, then the center would be the center of the neutral space, which is language specific). Based on this, you could actually map vowels onto these movements, if you wanted to. In fact, take a look at just the cardinal movements. Does that remind you of anything? Maybe something that could look like this:
| Front | Back | |
| High | i, y | ɯ, u |
| Mid | e, ø | ɤ, o |
| Low | a |
Pretty neat, huh? So if you're not fond of the capital XA, YK, etc. designations, vowels can serve your purpose. And once you come up with a romanization system for the vowels, you can probably add a diacritic which will mean "diagonal", so that you can get a letter mapping (e.g. add a diacritic to "i", and it's predictable which diagonal movement you get).
If you have a romanization like the above, it'll probably be fairly easy to come up with a method for romanizing secondary articulations like "augmentative", "diminutive", "quick", etc. For example, there are off-glides. So you could have "a" being an XY movement, and "aw" being an XZ movement (augmentative), "ay" being half of an XY movement (diminutive), "aa" being a quick XY movement, etc. It's largely dependent upon what your sign language chooses to encode (and, of course, your imagination).
•XIIID: Describing Handshape:
Handshape is slightly less straightforward than both place and movement (even though it does seem more concrete). Though a given handshape has a given symbol in SLIPA, there's no guarantee that there will be a one-to-one mapping between handshape symbols in SLIPA and the handshapes used by your signed language. One problem that's easily fixed is unique handshapes that just aren't up there yet (I'll try to update regularly). Sometimes, though, a given signed language will have subtle differences in handshape that aren't captured by SLIPA, and which won't be. For example, Taiwanese sign language distinguishes two handshapes that are very similar. One is the Ś handshape, and the other is a version of the Ś handshape with the middle and index fingers pulled together slightly, but not tightly, as with the Û handshape. The technical way to represent this second handshape would be [Ś(], but since the two handshapes are distinct, two different characters should be used in a romanization system.
Now for how to present these in a table. There are many, many different ways. At hand, I have three actual methods used by SLN (Sign Language of the Netherlands, which is referred to as NGT, Nederlandse Gebarentaal, in Dutch), BSL (British Sign Language), and TSL (Taiwanese Sign Language). I'll describe each system to give you an idea of how each language presents its possible handshapes:
- SLN/NGT Handshape: SLN/NGT has a neat table that divides the 70 handshapes of SLN into eight distinct groups. (You can see a .pdf I scanned of the page by clicking here.) Thus, each handshape is either a Group I handshape, or a Group II handshape, or a Group III handshape, or a Group IV handshape, etc. Each group is chosen according to how the hand is shaped. Previously, I had no idea what the groups were, because if you look at that chart, the writing is (a) in Dutch, and (b) really, really small. Luckily, Kilian Hekhuis, a Dutch speaker, e-mailed me, and was able to provide me with translations for each of the group titles (thanks, Kilian)! The groups listed, then, are (and you can refer to the page I scanned in while reading): Group I: Fist; Group II: Round open shape; Group III: Round closed shape; Group IV: Thumb opposite the other fingers; Group V: Flat shape; Group VI: One or two pointing/stretched fingers; Group VII: Three or more spread fingers; and Group VIII: The rest. Thus, handshapes are grouped together (roughly) by shape, and the label of each handshape is given directly underneath. That's a nice way to categorize and present them. (There is another method used for NGT, and when I read up on it, I'll post about it here.)
- BSL Handshape: The handshape listing I have for BSL has only 26 handshapes, so I don't know if it's a full list. But, given that they employ a two-hand manual alphabet, it very well might be. These handshapes aren't arranged according to shape, but are arranged in English alphabetical order based on the name of the handshape (A, B, etc.). Below each handshape, the symbol is given, as well as an explanation of how to form the handshape.
- TSL Handshape: TSL has 50 handshapes, and one...armshape (it's a handshape called "arm", and the picture is of an arm with a closed fist. Is that a handshape...?). Anyway, the table I have is very neatly arranged, with five columns of ten handshapes each (plus one at the bottom of the last column). The handshapes are arranged in semanto-logical order, so that unique handshapes for zero through nine come first (going from top to bottom, and then left to right), then it continues with numbers (from ten to ten thousand [though not by even intervals]), and then goes on to nouns/concepts. Here, it's my belief (though I'm not sure, as I can't read Chinese) that the order switches to alphabetical order by character. So each handshape not only has a name, but a specific character, and an associated meaning. Thus, you don't get "Ś handshape", you get "tiger handshape"; not "S handshape", but "fist handshape", etc. Like the table for SLN, though, there's no explanation as to how you form the handshape (but the picture should be enough, really).
So these are ideas on how to create a handshape table. One main drawback is that each of these tables has pictures of each handshape. That would be lovely, but it's not really possible. I would like to be able to include a .gif of each handshape I catalog on SLIPA, but I really wouldn't know how to go about that (I'm not good at computer graphic design, as evidenced by my drawings in the section on place). This is why the SLIPA page exists. You can use the handshape symbols above like IPA symbols, and someone who looks at your website can go to this site and see how those symbols translate into a handshape. Obviously this is not ideal, but the ideal way of doing it doesn't seem viable. At very least this can be a standard way of doing it. You can also describe each handshape on your page, though it does take up space.
And, again, the extra diacritics for handshape are there to better specify the exact handshape you want. So after describing your handshape as [Śv(s)>], you might give that transcription a name, and then only use that name thereafter. If someone sees the name and doesn't know what it means, they can go to your phonology page to see the transcription. And, if they don't know what the transcription means, either you can explain on your page, or they can come here. Hopefully those who become interested in CSL's (my own coinage for signed conlangs) will become familiar enough with the transcription that they won't need to be constantly flipping back and forth between pages. And, of course, the best presentation for a given CSL will hopefully tell the reader everything s/he needs to know without them having to go page-hopping.
•XIIIE: Some Further, General Comments:
Now that all this has been described, I want to reemphasize that I designed SLIPA to be an IPA. As such, it's primarily intended for transcription. I don't think SLIPA is a good orthography or romanization for a signed language, just like I don't think the IPA is a good orthography for any spoken language (if you've ever seen large blocks of text transcribed using the IPA, you know how hairy it can get). SLIPA is just a tool to help conlangers have a common ground for discussing signed languages. Once you've grounded the fundamentals of your CSL in SLIPA (or another transcription system), I then suggest you develop a romanization to more easily discuss things like handshape, place, etc. And then once that's in place, I suggest coming up with an orthography. An orthography can be nothing more than English words, like in ASL. So in ASL, English words denote, or stand for, a sign; they do not describe, or connotate, a sign. So the sign represented by the English word "COPY" has different connotations in different situations, but is always represented by the word "COPY". This doesn't mean it's how the word should be defined in all circumstances. Thus, you could use English words for your orthography as well. You might have a sentence like "I GO-RETURN TWO LIBRARY", which would mean "I went to the library and back twice". You use the word "TWO" because, in this imagined signed language, there's no lexical difference between "two" and "twice". But there are syntactic differences. So, going along with this imagined example, "I GO-RETURN LIBRARY TWO" would mean, "I went to two libraries and came back". Same sign; different syntactic structures; different meanings.
The point is this: I created SLIPA not to make things more difficult, but to make things easier, and more explicable. So use transcription where necessary, but when it's not, don't try to force it to be necessary.
XIV. Apologia/FAQ
In creating a signed language IPA, I had to make many compromises. This is a list of all the ones I can think of right now, and an explanation for why I made the choices I did. I imagine as I get more comments, this list will grow. For now, this is all there is:
- Q: Why do a lot of these symbols look like English/ASL words/signs?
- A: It's no coincidence that the place at the "elbow" is given the symbol /lbw/. Nor is it a coincidence that the B handshape is called a B handshape as opposed to a hand handshape (as in TSL). This is because I had to start somewhere. This website is in English, and I'm from America, and I recognize that a majority of the people that view this site will be familiar at the very least with English. Hopefully this will make the system easier to learn for people familiar with English. Nevertheless, /lbw/ is a symbol, and not a shortening of the English word "elbow". Each P refers to an area of the body which may not directly coincide with the English word from which it got its name. As for handshapes, while it's true that many of the names came directly from ASL, many did not. This is because I'm working with unicode. There is no "bent V" character in unicode right now. Further, I wanted to make the handshape table easier for conlangers. Thus, the names of handshapes are semi-related to common orthographic conventions used in spoken languages (e.g. handshapes related to the X handshape are transcribed using various letters commonly used for the sound [ʃ], because the grapheme "x" also commonly represents the sound [ʃ]). This is how I decided which character should correspond to which handshape. Some system had to be used, so I used this one. And, quite frankly, it's not too different from the IPA, which was heavily influenced by the roman alphabet, and Indo-European languages (though, of course, this is no excuse by itself).
- Q: Why is this system so complex (both in structure and style)?
- A: Well, signed languages aren't simple, of course. Further, though, it was really important to me to create a system that could be used over e-mail, on a listserv like CONLANG, where only ASCII characters get through (reliably). Thus, I had to resort to some rather complex-looking symbols and mechanisms. I saw no other way around it.
- Q: Why is SLIPA a linear transcription system, when sign language is inherently non-linear?
- A: Being independent of linearity is one of the great advantages of a system like SignWriting, and is, indeed, a disadvantage of SLIPA. But the reason it's a disadvantage of SLIPA is because it's a disadvantage of a system whose medium is an ASCII character set. Over e-mail, we're stuck with linearity, unless you use html when e-mailing (which much of the world doesn't). A non-linear system is useless if you can't force it into a linear framework. For that reason, I forced sign language into a linear transcription system. As a result, the system is inelegant in places, and, no doubt, inadequate in others. Like I said above, compromises had to be made, and I made them in favor of communicability, rather than fidelity.
- Q: So, I see place, movement, handshape, and...hey, where's orientation?
- A: Those familiar with a signed language, or with the literature about signed language, will undoubtedly notice the lack of a section devoted to orientation. How can this be, when orientation is said to be so direly important to all signed languages? Well, it bes, because there is no separate marker for "orientation" in SLIPA. Instead, orientation is handled in many ways. For example, the way the hand faces, or how it's bent, is handled with diacritics on handshapes symbols. Whether the hands face a particular P or face away from a particular P are handled by diacritics on the P symbols. And the path and direction of movement are all handled with movement symbols. Thus, orientation falls directly (though rather clunkily) out of the system already presented. To try to come up with a separate set of symbols for "orientation" would be far too unwieldy, and would turn out to be even more complex than the system I came up with, in my opinion. However, if someone can think up a system that treats orientation separately from place, movement and handshape, I'd be anxious to see how it works.
- Q: I can invent a far better system than SLIPA. Why should I use yours?
- A: If you can (a comment on the first sentence), you shouldn't (answer to the second). SLIPA is intended to be a tool not the tool. This is the best I could do (right now); not the best that can be done. I've no doubt that a better transcription system exists. If you've got a better transcription system, put it online somewhere; let us all know about it. As I've said before, the more systems, the better; I'm not looking for a patent, or anything. The goal is to facilitate the transcription and creation of signed language. If a different system can do it better, that's the system that should be used.
- Q: Do you intend for SLIPA to be a writing system that a Deaf signer would use in their everyday life?
- A: Emphatically no. SLIPA is an international phonetic alphabet, along the lines of the IPA (used for spoken languages). The IPA is used to transcribe speech sounds, and while it's not equally complex (it's a linear system transcribing the [mostly] linear sound systems of spoken languages), it's cumbersome, and difficult to write quickly—especially if one intends to do a narrow (i.e. as accurate as possible) transcription. The virtues of a (largely) phonemic orthographic system cannot be extolled enough. My comments above regarding the use of other systems is related primarily to their use as a method of transcription (though in certain cases I have remarked on their use as orthographies, as well). I in no way intend SLIPA to be used as an orthography for any signed language system of any kind.
- Q: Is SLIPA a signed version of the written IPA?
- A: No, it isn't. I used the IPA in the name simply because it's handy and memorable (and also because the system is international [i.e. intended to handle any sign language, not just ASL, for example] and phonetic). Other than the name, SLIPA has nothing in common with the written International Phonetic Alphabet devised by the International Phonetic Association. Now, as I recall, there is a method that Deaf linguists use to sign the IPA, but I can't find anything on the web about it. If anyone can find a web resource e-mail me and I'll include it here.
- Q: I have questions/comments about SLIPA. Can I e-mail you?
- A: Sure; just go to the contact section and click on the link. If you have a couple suggestions, or a few ideas for improvement, I'd love to hear them, and may incoporate them. If you have many suggestions and ideas for improvement, I'd love to hear them, but rather than try to incorporate them, I'll probably encourage you to create your own system (especially if they're a radical departure from what I've already got up). Nevertheless, I'd love to hear any comments that anyone might have.
- Q: I've discovered feature X in Y sign language, and SLIPA can't handle it. What gives?
- A: Hopefully SLIPA can be modified to handle any feature of any signed language. This doesn't mean that it can currently handle every feature. Why? To put it bluntly, my knowledge of signed languages is limited. I know not enough ASL, and only what I've read from books or learned first-hand from Dr. Perlmutter. Unlike with spoken languages, you can't simply go to a community college and learn BSL, or SLN, or TSL, or JSL, or SSL. I don't even know if you could do this at Gallaudet University. (No, I see that you can't: "Although the department does not offer formal instruction in foreign sign, it does introduce students to selected elements of foreign sign language." Go here for their page on foreign language instruction, from which the preceding quote was extracted.) Further, cross-linguistic studies of the sign languages of the world are all but absent from the field of linguistics. This is a huge field whose surface has barely been scratched, and it will be very exciting to follow cross-linguistic sign language research in the coming decades. At this point in time, though, you've got to rob and steal for whatever info you can get. This page is based on an appallingly small amount of information, but it's the best I could muster. As the years go by, I'll learn more, and will change the page accordingly. And, of course, this means if you're from another country and have knowledge of a different signed language, you are an invaluable resource! Any info you have about the signed languages used in your country can only help a sign language transcription system.
To conclude, if you have any more questions, just let me know. If they're sufficiently important, I'll include them here.
XV. Conclusion
This is SLIPA. I've worked hard on it, and appreciate that you've taken the time to look it over. In the future, as people develop signed conlangs (CSL's—I need to remember to use my new term!), I'd like to include a links section on this page to CSL's online. So far, there are zero, but I'm working on one. Anyway, from the bottom of my heart, I thank you for looking this over. Happy conlanging, and happy signing!
XVI. References
In coming up with this system and designing this page, I'm indebted to several sources. This is a short list of them.
- Anonymous. Signuno = Esperanto + Gestuno : Esperanto sign language.
http://www.geocities.com/signuno/, 2005. - Bar-Tzur, David. International gesture: Principles and gestures.
http://www.theinterpretersfriend.com/indj/ig.html, 2002. - Be'erli, Itai. "SIPA - Excellent!". E-mail to the author. Aug. 31, 2007.
- Be'erli, Itai. "SIPA article, sections 5 & 6 - some comments". E-mail to the author. Sep. 1, 2007.
- Bodensohn, Andreas. "Your SLIPA". E-mail to the author. Apr. 28, 2007.
- Hanke, Thomas & Constanze Schmaling. syncWRITER - Integrating Video into the Transcription and Analysis of Sign Language.
http://www.sign-lang.uni-hamburg.de/Projects/HamNoSys.html, 2004. - Hanke, Thomas & Siegmund Prillwitz. Institut für Deutsche Gebärdensprache.
http://www.sign-lang.uni-hamburg.de/Artikel/1/Muenchen.html, 1994. - Hekhuis, Kilian. "SLIPA / SLN". E-mail to the author. Jan. 9, 2007.
- Hekhuis, Kilian. "RE: SLIPA / SLN [resend]". E-mail to the author. Feb. 9, 2007.
- Lytle, Steven. "SLIPA: SignWriting in Unicode". E-mail to the author. Aug. 31, 2021.
- Lytle, Steven. "typo in SLIPA description". E-mail to the author. Jan. 18, 2024.
- Lytle, Steven. "SLIPA-57 typos?". E-mail to the author. Feb. 6, 2024.
- Lytle, Steven. "typo right before SLIPA 50". E-mail to the author. Feb. 6, 2024.
- Lytle, Steven. "Typo right before SLIPA 43". E-mail to the author. Feb. 12, 2024.
- Lytle, Steven. "Missing word before SLIPA 49". E-mail to the author. Feb. 12, 2024.
- Lytle, Steven. "typo before SLIPA 55". E-mail to the author. Feb. 12, 2024.
- Lytle, Steven. "missing word (?) before SLIPA 12". E-mail to the author. Feb. 13, 2024.
- Lytle, Steven. "typo before SLIPA 37". E-mail to the author. Feb. 12, 2024.
- Mandel, Mark A. ASCII-Stokoe Notation: A Computer-Writeable Transliteration System for Stokoe Notation of American Sign Language. http://mark.cracksandshards.com/ASCII-Stokoe.html, 2007.
- Mandel, Mark A. "ASCII transliteration system for Stokoe notation". E-mail to the author. Oct. 17, 2012.
- Martin, Joe. A Linguistic Comparison - Two Notation Systems for Signed Languages.
http://www.signwriting.org/forums/linguistics/ling008.html, ~2000. Download .pdf - Perlmutter, David M. "Sonority and Syllable Structure in American Sign Language", Linguistic Inquiry, Vol. 23, No. 3, pp. 407-442, 1992.
- Rosenberg, Amy. Amy Rosenberg Thesis University Kansas.
http://www.signwriting.org/forums/research/rese010.html, 1999. - Stone, Thomas. American Sign Language - Sign Jotting. http://aslsj.com/, 2009.
- Sutton, Valerie. DanceWriting: Read and Write Dance. http://www.dancewriting.org/, 2004.
- Sutton, Valerie. SignBank SignPuddle: Sign Language Software in SignWriting. http://www.signbank.org/, 2004.
- Sutton, Valerie. SignWriting: Read, Write Sign Languages. http://www.signwriting.org/, 2004.